相关试卷
-
1、若在二进制整数1001的最右边添加两个0形成一个六位二进制数,则新数的值是原数值的 ( )A、2倍 B、100倍 C、10倍 D、4倍
-
2、下列叙述中,正确的是( )A、信息作为一种特殊资源,具有绝对的使用价值,能够满足人们的需要 B、在利用计算机解决问题之前,我们首先需要给出解决问题的详细方法和步骤 C、程序设计简称编程,也属于编码 D、一个算法所包含的计算机步骤是无限的
-
3、某医院挂号系统有两种挂号方式:预约挂号(预约就诊时间,需提前一天完成)和直接挂号(当天8:00后在服务台排队挂号)。医生8:00开诊;预约挂号患者在预约的就诊时间到达后,优先就诊;一位患者就诊结束后,下一位患者再开始就诊。
医院为提升服务质量,编写程序模拟就诊顺序。现获取某医生早上就诊患者的数据,分别为姓名、预约或挂号时间、就诊时长(单位:分钟)。预约挂号数据(准时到达人员数据)如图a所示,直接挂号数据如图b所示。运行程序,输出前三位就诊顺序名单,如图c所示。



图 a
图 b
图 c
(1)、根据上图数据,预约挂号人员江浩华排在第位就诊。(2)、定义如下sort(lst)函数,参数lst的每个元素都包含3个数据项,分别为姓名、预约时间、就诊时长。函数功能是将lst的元素根据预约时间进行升序排列,函数返回lst。函数代码如下,请在划线处填入合适的代码。def sort(lst) :
n=len(lst)-1
for i in range(n-1) :
for j in range(n,i+1,-1) :
if:
lst[j],lst[j-1]=lst[j-1],lst[j]
return lst
(3)、实现模拟输出就诊顺序的部分 Python 程序如下,请在划线处填入合适的代码。def insert(lst,i,head) :
curtime=lst[head] [1]+int(lst[head] [2]) #就诊结束时间
if :
lst[i].append(head)
head=i
curtime=lst[i] [1]+int(lst[i][2])
i+=1
q=lst[p] [3]
while i<=len(lst)-1 :
if curtime>=lst[q][1] and q!=-1 : #预约人员优先就诊
p=q
q=lst[p] [ ]3
curtime+=int(lst[p][2])
elif curtime>=lst[i] [1] or q==-1 :
lst[i].append(q)
curtime+=int(lst[i] [2])
p=i
i+=1
elif lst[q] [1]<=lst[i] [1]:
curtime=lst[q] [1]
else :
curtime=lst[i] [1]
return lst
#预约挂号数据转换为列表 lst,并将时间转换为分钟,如 08:30 转为 510,代码略
lst=sort(lst)
n=len(lst)-1
for i in range(1,n) :
lst[i].append(i+1) #lst[i]追加一个元素 i+1
lst[n].append(-1)
#将门诊挂号数据合并至列表 lst 中,列表 lst数据如图d所示,代码略 head=1
lst1=insert(lst,n+1,head)
#输出就诊顺序,代码略
 图 d
图 d -
4、小明收集了某超市部分商品2022年上半年每天的价格数据并保存在"data.xlsx"文件中,如图a所示。
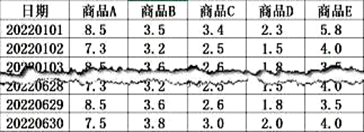 图 a
图 a要分析某商品一个月内的价格稳定情况,需要将本月每天(除第一天外)价格波动的绝对值加起来(价格波动=当天价格-前一天价格),其值越小,价格越稳定。
为统计该超市6月份各商品价格稳定情况,编写如下Python程序。请回答下列问题:
import pandas as pddf = pd.read_excel("data.xlsx")
df = _____________________
df = df.reset_index(drop=True) # 重新设置索引,从0开始递增
(1)、获取 6 月份各商品的价格,划线处填入的代码为_______ (多选,填字母)A、df[df["日期"] >= 20220601] B、df["日期" >= 20220601] C、df[df.日期 >= 20220601] D、df[df["日期"]] >= 20220601(2)、绘制6月份价格稳定情况线形图,部分Python程序如下,请在划线处填入合适的代码。import matplotlib.pyplot as plt
cols = df.columns[1:] #存储各商品名称
n =
m = len(cols)
diff = [0]*m
for i in range(m):
s = 0
for j in range(1, n):
day_diff = abs(df[cols[i]][j]-df[cols[i]][j-1]) # 计算每天价格波动
s+=day_diff
x,y = cols,diff
plt.
plt.show ()
(3)、由图b可知,该超市6月份各商品价格最稳定的是______ (单选,填字母) 图 bA、商品 A B、商品 B C、商品 C D、商品 D E、商品 E
图 bA、商品 A B、商品 B C、商品 C D、商品 D E、商品 E -
5、小明搭建了室内温度监测信息系统,该系统结构示意图如图 a 所示。Web 服务 器端程序采用Flask Web 框架开发。请回答下列问题:
 图 a(1)、小明想利用智能终端结合温度传感器,实时监测室内温度变化情况,这一过程属于搭建信息系统前期准备中的 (单选,填字母:A .需求分析 / B .可行性 分析 / C .详细设计) 。(2)、图 a 中①处应填入(单选,填字母:A .路由器 /B .防火墙 /C .数据库)。
图 a(1)、小明想利用智能终端结合温度传感器,实时监测室内温度变化情况,这一过程属于搭建信息系统前期准备中的 (单选,填字母:A .需求分析 / B .可行性 分析 / C .详细设计) 。(2)、图 a 中①处应填入(单选,填字母:A .路由器 /B .防火墙 /C .数据库)。 图 b(3)、该系统网站功能页面规划如图b 所示,智能终端的部分代码如下,从代码中 可以看出,连接温度传感器的引脚是 , 连接执行器的引脚是。
图 b(3)、该系统网站功能页面规划如图b 所示,智能终端的部分代码如下,从代码中 可以看出,连接温度传感器的引脚是 , 连接执行器的引脚是。while True:
temp=round((pin1.read_analog ()/1024)*3000/10.24,1)
errno,resp=Obloq.get("input?id=1&val="+str(temp),10000)
if errno == 200 :
display.show (str(resp))
if resp =="1" :
pin8.write_digital(1)
else:
pin8.write_digital(0)
else:
display.show (str(errno))
sleep(1000*5)
(4)、若传感器的编号id为1,温度val值为30,提交数据到服务器的URL为。(5)、从数据库中获取了最近100次传感器采集到的温度数据,按时间先后顺序依次存储在列表a中,要计算最近十次的平均温度(sum的初值均为0,温度数据均正常),下列Python程序段符合要求的有 (多选,填字母) 。A、for i in range(10):sum+=a[i]
ave=sum/10
B、for i in a[-10:] :sum+=i
ave=sum/10
C、i=90while i<=99 :
sum+=a[i]
i+=1
ave=sum/10
D、i=-1while i>=-10 :
sum+=a[i]
ave=sum/10
-
6、有如下 Python 程序段:
import random
a= [0]*6
for i in range(1,6) :
a[i]=random.randint(1,9)
if i%2==a[i]%2:
a[i]+=1
else:
a[i]+=a[i-1]
执行该程序段后,a的值不可能的是( )
A、[0, 4, 5, 7, 12, 10] B、[0, 8, 9, 8, 16, 21] C、[0, 8, 5, 10, 19, 4] D、[0, 4, 7, 15, 9, 6] -
7、有如下 Python 程序段:
d= [1,3,8,15,22,26,28,40,46,61,80]
i=0;j=len(d)-1
while i<=j:
m= (i+j)//2
if key<d[m] :
j=m-1
else:
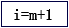
若 key 值为 22,程序运行结束后,加框处语句执行的次数为( )
A、1 B、2 C、3 D、4 -
8、定义如下函数:
def f(x):
if x<=1 :
return 2
else:
return f(x-1)*2+f(x-2)
执行语句 v=f(3),v 的值为( )
A、10 B、12 C、14 D、16 -
9、有一棵二叉树如图所示,下列说法正确的是( )
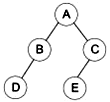 A、该二叉树是一棵完全二叉树,树的高度为 3 B、该二叉树的前序遍历为 A,B,D,C,E C、该二叉树的叶子节点有4个 D、该二叉树的建立只能使用数组来实现
A、该二叉树是一棵完全二叉树,树的高度为 3 B、该二叉树的前序遍历为 A,B,D,C,E C、该二叉树的叶子节点有4个 D、该二叉树的建立只能使用数组来实现 -
10、有一空栈S,对待进栈的数据元素序列a,b,c,d,e,f依次进栈、进栈、出栈、进栈、进栈、出栈的操作,操作完成后,栈S的栈顶元素是( )A、c B、d C、e D、f
-
11、下列 Python 表达式的值最大的是( )A、abs(int(-5.8)) B、int("87654321"[3:4]) C、ord("F")-ord("A") D、17%3**3//2-2
-
12、下列关于网络系统的说法,正确的是( )A、网络中的资源是指网络中所有的数据资源 B、传输控制协议 TCP 负责将信息从一个地方传送到另一个地方 C、计算机网络按网络的覆盖范围可以分为局域网、广域网、互联网 D、网络中的计算机系统终端可以是 PC 机、笔记本电脑、手机、平板电脑等
-
13、阅读下列材料,完成问题
可视化物流信息系统主要由卫星定位终端、RFID电子标签、控制中心等部分组成,能够对运输中的货物全过程监控,对数据进行实时集成,从而实现物流网络的信息化。客户可以通过手机号码、货物单号等在手机APP或网页端上查看相关物流信息。
(1)、以下不属于该信息系统硬件的是( )A、物流车辆上的卫星定位终端 B、货物上的 RFID 电子标签 C、控制中心的服务器 D、物流信息系统中的数据库(2)、下列有关该信息系统中数据的说法,正确的是( )A、通过 RFID 电子标签采集货物物流信息,使用了传感器技术 B、货物单号不用在数据库中存储 C、服务器不会更新货物在运输过程中的位置信息 D、只能在客户端查询货物的物流信息(3)、下列关于该信息系统安全的说法,正确的是( )A、为提升数据的传输速率,关闭服务器防火墙 B、物流信息中的客户手机号码属于个人一般信息 C、可通过磁盘阵列、数据备份、异地容灾等手段,保证数据的安全 D、对数据库中的敏感信息进行加密就可以防止数据的泄露 -
14、下列关于人工智能的说法,不正确的是( )A、问题引导下的试错学习是人工智能的一种典型学习方式 B、符号主义认为智能行为就是对符号的推理和运算 C、依赖于领域知识和数据的人工智能被称为领域人工智能 D、人工智能技术不断地推动人类社会进步,不可能威胁人类安全
-
15、下列关于数据和信息的说法,正确的是( )A、数据的种类和形式都是固定的 B、单纯的数据是没有意义的 C、信息经过加工、处理、分析后,一定能更好的被人们所使用 D、同一种信息不能同时被不同的接收者获取
-
16、图书查询。所有正版图书均有唯一的国际标准书号(ISBN),ISBN由13位数字和字符“-”组成,字符“-”对数字间隔分段。如:某图书的ISBN为“978-7-5536-3176-9”(其中“978”表示图书类代码,“7”表示地区码,“5536”表示出版社代码,“3176”表示书序码,“9”为校验码)。小李为某校园书吧编写了图书查询的程序。
 (1)、主程序
(1)、主程序lst1=readfile("in.csv")# 校园书吧库存图书信息存储在文件"in.csv"
while True:
print("1.验证 ISBN 校验码; 2.统计出版社费用; 3.操作结束")
opt=int(input("请输入操作编号(1-3):"))
if opt==1:
isbn=input("请输入 ISBN 号:")
if check(isbn):
print("校验码正确")
else:
print("校验码错误")
elif opt==2:
code=input("请输入出版社代码:")
money=total(code)
print("书吧中该出版社出版的图书总价:%.2f 元" %money) #输出的总金额保留 2 位小数点
else:
print("操作结束")
break
运行程序,若输入opt值为 4,程序将(单选,填字母;A .运行时报错/ B .输出“操作结束”)。
(2)、读写文件小李将校园书吧库存图书信息存储在文件"in.csv"中,内容如图所示。函数readfile()用于逐行读取文件数据存入列表并返回。请在划线处填入合适的代码。
import pandas as pd
def readfile(filename): #读 csv 格式文件内容,将其存入列表并返回
df1=pd.read_csv(filename, encoding="GBK")
lst=[]
for i in df1.index:
isbn=df1["ISBN"][i]
num=df1["图书数量"][i]
price=df1["单价 (元) "][i]
#添加到列表
lst.append([isbn,num,price])return
(3)、校验码验证ISBN最后一位的校验码用来检验前12位数字是否准确,是保护知识产权的一种检验方法。计算方法如下:
①将ISBN中前12位数字从左到右依次编号为“1、2、3、……、12”。
②若数字编号是奇数,则对应权值为1,否则权值为3。首先将ISBN中前12位的数字值与对应权值相乘,然后将计算所得值进行累加。
③最后,用10减去第②步结果对10整除的余数,所得结果即为校验码。
defcheck(ISBN): #对ISBN校验码验证
n=len(ISBN)
val=0; k=3
for i in range(0,n-1):
if '0'<=ISBN[i]<='9':
k=4-k
val+=int(ISBN[i])*k
if result==int(ISBN[-1]):
return True
else:
return False
(4)、统计校园书吧中某出版社出版的所有图书总价'''列表 lst1 中的部分数据如:
[['978-7-5139-3066-6',7,59.80],['978-7-5063-3174-6',9,48.00] , ……]
'''
def total(code): #统计书吧中出版社代码为 code 的所有图书总价
n=len(lst1);money=0
for i in range(n):
isn=lst1[i][0].split('-') #将 list1[i][0]以“- ”为分隔符,分割成多个字符串组成的列表
if isn[2]==code:
return money
-
17、小陈准备为班级植物区搭建植物环境监测系统,该系统每隔30分钟对土壤温湿度进行一次监测,当土壤日平均湿度低于临界值时,系统自动对植物进行浇水,以保障检测期间的植物生长土壤日平均湿度在17%~44%范围内。系统结构示意图如图a所示。
 图 a(1)、根据信息系统的功能要求,图中①处的设备名称是(单选,填字母:A .路由器/ B .交换机/ C .智能终端)(2)、该系统服务器端程序采用FlaskWeb框架编写,服务器的IP地址是192.168.1.10,端口号为8000,若要查看传感器采集的数据,应访问的页面地址是 http://。(3)、将数据库中4月中旬的土壤温湿度数据导出为文件“day.xlsx”,如图b所示。并制作4月中旬(十天)的土壤日平均湿度变化情况,如图c所示,部分代码如下,请在划线处填入合适的代码。
图 a(1)、根据信息系统的功能要求,图中①处的设备名称是(单选,填字母:A .路由器/ B .交换机/ C .智能终端)(2)、该系统服务器端程序采用FlaskWeb框架编写,服务器的IP地址是192.168.1.10,端口号为8000,若要查看传感器采集的数据,应访问的页面地址是 http://。(3)、将数据库中4月中旬的土壤温湿度数据导出为文件“day.xlsx”,如图b所示。并制作4月中旬(十天)的土壤日平均湿度变化情况,如图c所示,部分代码如下,请在划线处填入合适的代码。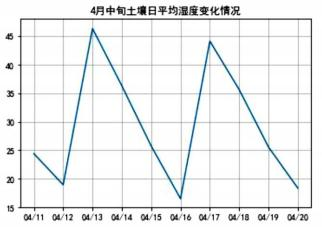
图 b
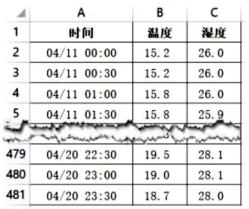
图 c
import pandas as pd
import matplotlib.pyplot as plt
#图表显示中文字体,代码略
df=pd.read_excel("day.xlsx") #读取 Excel 文件中的数据
data=[]
for t in df["时间"]: #从“时间”格式中提取日期数据
data.append( )
df["日期"]=data #添加一列数据, 列标题为“日期”
df1=df.groupby("日期", as_index=False).mean()
x=df1["日期"]
y=
plt.ylim(10,30) #设置 y 轴的坐标范围
plt.title("4 月中旬土壤日平均湿度变化情况") #设置图表标题
plt.plot(x,y) #绘制折线图
plt.show()
(4)、分析如图c所示的“4月中旬土壤日平均湿度变化情况”图表可知,该系统在运行期间对植物生长土壤的湿度控制(选填:达到/未达到)预期目标。 -
18、某 Python 程序如下:
p=")!@#$%^&*("
c="cra2edu"
t=""
for i in range(len(c)//2+1):
if i%2==0:
t+=c[len(c)-i-1]
elif c[i]>="0" and c[i]<="9":
t+=p[int(c[i])]
else:
t+=c[i]
print(t)
程序运行后,输出的结果是( )
A、ure@ B、ure@a C、ude@ D、cda! -
19、阅读下列材料, 回答问题。
技术员小王要为农场工作人员搭建一个智慧农场监测系统。智能终端接收传感器的温度、湿度和光线数据,并将数据传送到服务器,保存到数据库,数据库采用SQLite数据库。用户通过手机专用客户端App访问服务器,可以查看系统状态并做出相应的设置,服务器将处理的结果经IoT模块传送给智能终端,由智能终端启动执行器实现对温度、湿度和光线的控制。
(1)、下列组合属于该信息系统软件的是( )①小王 ②手机专用客户端 ③传感器数据 ④服务器端操作系统 ⑤SQLite
A、①②④ B、②④⑤ C、②③⑤ D、③④⑤(2)、下列组合中,全部都是搭建该信息系统所需的传感器的是( )A、声音传感器和温度传感器 B、温度传感器和距离传感器 C、湿度传感器和光线传感器 D、光线传感器和气体传感器(3)、根据阅读材料,下列说法不正确的是( )A、该信息系统采用 C/S 网络架构 B、小王属于该信息系统的用户 C、智能终端可以不通过无线网就能接收传感器的数据 D、农场工作人员无需接入互联网就能管理该信息系统 -
20、阅读下列材料, 回答问题。
某饮品店采用会员积分消费模式。顾客扫描店铺二维码关注公众号,输入手机号及个人资料注册后即成为普通会员,每消费10元可积1分。消费积分累计100分,升级为V1会员,享受8折消费优惠;消费积分累计180分,升级为V2会员,享受7折消费优惠。
(1)、根据阅读材料, 下列说法正确的是( )A、顾客扫描二维码只能获取到文本信息 B、店铺生成二维码的过程属于信息的解码 C、二维码在使用过程中不存在安全隐患 D、通过智能手机应用程序可读取二维码中的信息(2)、用 Python算法控制结构描述“消费积分累计100分,升级为V1会员;消费积分累计180分,升级V2会员”,设t为顾客的消费积分,下列选项正确的是( )A、if t>=100:print("升级为 V1 会员")
elif t>=180:
print("升级为 V2 会员")
B、if t>=180:print("升级为 V2 会员")
else:
print("升级为 V1 会员")
C、if t>=100 and t<180:print("升级为 V1 会员")
else:
print("升级为 V2 会员")
D、if t>=180:print("升级为 V2 会员")
elif t>=100:
print("升级为 V1 会员")