相关试卷
- 浙江省七彩阳光新高考研究联盟2025-2026学年高二上学期期中联考技术试题-高中信息技术
- 浙江省台州市十校联盟2025-2026学年高二上学期期考试技术试题-高中信息技术
- 重庆市黔江实验中学2025-2026学年高三上学期期中信息技术试题
- 云南省玉溪一中2024-2025学年上学期期末学业水平合格性考试模拟卷信息技术试卷
- 贵州省贵阳市2024-2025学年高一下学期7月期末信息技术试题
- 江苏省南通市2024-2025学年高一上学期1月期末信息技术试题
- 四川省内江市2024-2025学年高一下学期期末检测题技术试卷
- 上海市浦东新区上海师范大学附属中学2024-2025学年高一上学期10月期中信息技术试题
- 海南省临高县第二中学2024-2025学年高一上学期期中考试信息技术试题
- 江苏省徐州市2024-2025学年高一下学期期末抽测信息技术试题
-
1、题图为计算机硬件系统的组成与工作原理,其中1、2处的硬件名称分别是( )
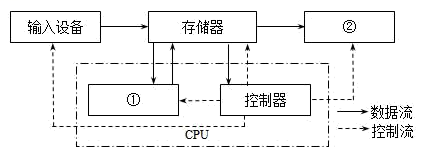 A、运算器、输出设备 B、显示器、扫描设备 C、计算器、打印设备 D、编辑器、输出设备
A、运算器、输出设备 B、显示器、扫描设备 C、计算器、打印设备 D、编辑器、输出设备 -
2、下列关于算法输入、输出特征的描述,不正确的是( )A、可以有多个输入 B、可以没有输入 C、只能有一个输出 D、必须要有输出
-
3、下列属于人工智能中模式识别技术应用的是( )A、用手机打电话 B、光学字符识别 C、讨论考试数据 D、阅读电子报刊
-
4、在Python语言中,下列合法的变量名是( )A、6flower B、if C、it_6 D、i-6
-
5、下列属于计算机输入设备的是( )A、显示器 B、鼠标 C、打印机 D、耳机
-
6、下列属于图像采集工具的是( )A、照相机 B、打印机 C、温度计 D、录音笔
-
7、下列关于信息概念的描述,正确的是( )
①信息一定包含声音 ②符号可以表达信息 ③声音可以表达信息 ④图像可以表达信息
A、②③④ B、①③④ C、①②④ D、①②③ -
8、在Python语言中,算术表达式“721/10”的执行结果是( )A、2 B、10 C、72.1 D、0
-
9、下图为求“实数x绝对值”问题的算法流程图,在1处应该填入( )
 A、x=0 B、x=-y C、y=x D、y=0
A、x=0 B、x=-y C、y=x D、y=0 -
10、在Python语言中,已知L=[74,81,56, 90],则max(L)运行结果是( )A、90 B、81 C、56 D、74
-
11、在Python语言中,能正确表示条件“x大于等于6,并且小于17”的表达式是( )A、x>=6 or x>17 B、x<=6 and x<17 C、x<=6 or x>17 D、x>=6 and x<17
-
12、在Python语言中,已知a=7,b=9,下列运行结果为True的是( )A、not a!=b B、a==b C、a>=b+1 D、a<=b
-
13、在Python语言中,已知a=5,b=6,下列运行结果为False的是( )A、not a==b B、a+2>b C、a!=b D、a>=b
-
14、在Python语言中,运行以下代码后,变量i的值是( )
i=0
while i<6:
print
i=i+1
A、0 B、6 C、1 D、7 -
15、某同学购买了一款正版软件,未经许可把该软件发送给他人共享。这种做法属于( )A、互相帮助 B、正常交流 C、侵犯版权 D、资源共享
-
16、下列不属于操作系统的是( )A、IOS B、WinRAR C、Windows D、Android
-
17、在网络时代,网络系统安全尤为重要。下列属于保障网络安全的逻辑技术措施是( )A、环境维护 B、数字认证 C、防雷击 D、预防盗窃
-
18、下列不属于计算机网络设备的是( )
①显示器 ②键盘 ③交换机 ④路由器
A、①② B、①④ C、②③ D、③④ -
19、下列属于计算机网络主要功能的是( )A、音频编辑 B、视频编辑 C、程序设计 D、资源共享
-
20、某班级学生使用班级群讨论学习方法。这体现的是信息技术可以改变人们的( )A、管理方式 B、交流方式 C、生活方式 D、娱乐方式