相关试卷
- 浙江省七彩阳光新高考研究联盟2025-2026学年高二上学期期中联考技术试题-高中信息技术
- 浙江省台州市十校联盟2025-2026学年高二上学期期考试技术试题-高中信息技术
- 重庆市黔江实验中学2025-2026学年高三上学期期中信息技术试题
- 云南省玉溪一中2024-2025学年上学期期末学业水平合格性考试模拟卷信息技术试卷
- 贵州省贵阳市2024-2025学年高一下学期7月期末信息技术试题
- 江苏省南通市2024-2025学年高一上学期1月期末信息技术试题
- 四川省内江市2024-2025学年高一下学期期末检测题技术试卷
- 上海市浦东新区上海师范大学附属中学2024-2025学年高一上学期10月期中信息技术试题
- 海南省临高县第二中学2024-2025学年高一上学期期中考试信息技术试题
- 江苏省徐州市2024-2025学年高一下学期期末抽测信息技术试题
-
1、阅读材料,回答问题
小郑为家庭搭建了“校园室内环境实时监测系统”,其中使用智能终端监测室内温度、湿度等数据并将数据传输至服务器进行存储与处理。该系统结构示意图如图所示。Web 服务器端程序采用 Flask Web框架开发,传感器采集的数据由智能终端经IoT模块发送到Web服务器,执行器用于实现室内温湿度、通风和报警控制。请回答下列问题:
(1)、有关搭建该系统所采用的开发模式特点描述中,不正确的是( )A、该系统架构的应用程序的升级和维护都可以在服务器端完成,降低了成本和工作量 B、该架构服务器的负荷较重,对网络的依赖性较高 C、该系统为B/S架构,是对 C/S 架构改进后产生的一种软件系统体系结构 D、该架构可以充分利用客户端与服务器端的硬件环境的优势,将任务合理地分配到客户端和服务器端(2)、下列关于上面“校园室内环境实时监测系统”的说法中不正确的是( )A、组成该系统的硬件部分主要包含网络设备、传感设备、Web 服务器、智能终端等 B、该信息系统由硬件、软件和用户三部分构成 C、该信息系统在断电的情况下无法运行,说明该系统对外部环境有依赖性 D、若该信息系统使用数据库存储数据,则服务器端需要安装数据库管理系统 -
2、某算法流程图如图所示,若输入 x 的值为 10,则该算法执行后,下列说法正确的是( )
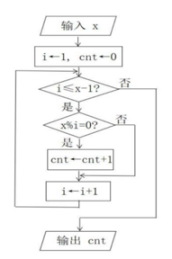 A、x%i=0执行了 3次 B、变量 cnt的值为3 C、变量 i的值为9 D、循环体执行次数为4
A、x%i=0执行了 3次 B、变量 cnt的值为3 C、变量 i的值为9 D、循环体执行次数为4 -
3、下列关于数据的说法,正确的是( )A、大数据分析时,要确保每个样本准确,以便探求事物因果关系 B、信息是数据经过存储、分析及解释后所产生的意义 C、模拟数据数字化的过程是先量化然后再采样 D、计算机只能处理二进制和十六进制的数据
-
4、下列关于程序设计语言的叙述,正确的是( )A、高级语言就是自然语言 B、汇编语言是一种高级语言 C、计算机能直接识别机器语言 D、高级语言是由0~9十个数字组成的十进制代码
-
5、在Python语言中,运行以下代码后,变量i的值是( )
i=6
while i>=2:
print (i)
i=i-1
A、6 B、0 C、1 D、2 -
6、在Python语言中,运行以下程序段后,显示的结果是( )
>>> a=8
>>> b=2
>>> a-=b
>>> b+=a
>>> a+b
A、10 B、14 C、8 D、12 -
7、下列哪一个属于数据库应用系统( )A、图书销售系统 B、Flash动画制作软件 C、windows 10 D、Word文字处理软件
-
8、在Python语言中,算术表达式“56//10”的执行结果是( )A、5 B、0 C、6 D、10
-
9、下列可用于标识物联网中某物品信息的代码名称是( )
①二维码 ②智能码 ③条形码 ④交换码
A、②④ B、②③ C、①④ D、①③ -
10、以下哪一种不是算法的结构?( )A、顺序结构 B、分支结构 C、循环结构 D、线性结构
-
11、将二进制数10110转换为十进制数,下列正确的是( )A、19 B、20 C、21 D、22
-
12、下列属于人工智能中模式识别技术应用的是( )A、交通信号控制 B、阅读电子报刊 C、用鼠标画图表 D、人脸识别支付
-
13、在Python语言中,属于保留字的是( )A、name_ 2 B、f+4 C、2lay D、for
-
14、下列全属于计算机输出设备的是( )A、话筒、打印机 B、耳机、摄像头 C、显示器、绘图仪 D、扫描仪、显示器
-
15、程序设计语言中最接近人类自然语言的是( )A、高级语言 B、翻译语言 C、机器语言 D、汇编语言
-
16、某学生管理系统主要由设计者、数据资源、网络、计算机等元素组成。其中“计算机”属于信息系统组成元素中的( )A、数据 B、软件 C、硬件 D、用户
-
17、网络带宽是衡量网络传输速度的一个重要指标,带宽格式书写正确的是( )A、MB/s B、KB/s C、Mb/s D、B/s
-
18、在Python语言中,执行“int (7.8)”函数后的结果是( )A、8 B、7.8 C、78 D、7
-
19、将模拟信号转换为数字信号的过程包含采样和( )A、解密、量化 B、压缩、编码 C、量化、编码 D、压缩、量化
-
20、将十进制数24转换为二进制数,下列正确的是( )A、11011 B、11000 C、11001 D、11010