相关试卷
-
1、小李创作题为“闻鸡起舞”的多媒体作品。他首先使用Photoshop软件制作一张图片,
然后使用Flash软件制作动画。请回答下列问题:
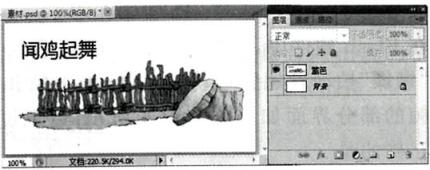
如图所示,“背景”图层图像颜色为白色,“篱笆”图层的图像背景也为白色。若只使“篱笆”图层中的“闻鸡起舞”消失,下列操作方法中正确的有(多选,填字母:A .用“橡皮擦”擦除“闻鸡起舞”;B .用“魔棒”选择白色区域,反选后删除;C .用矩形选框选中“闻鸡起舞”区域后删除;D .设置“拾色器”的前景色为白色,用“画笔”对“闻鸣起舞”进行涂画)。
-
2、如图所示,在Photoshop中合成背景图片时,从“no15-素材.psd”中选取“月精灵”图层中的图案,可以实现的工具有(选填:A .矩形选框\B .魔棒\C .磁性套索\D .裁剪)

-
3、用下列方式获得的图像中,属于矢量图的是( )A、用超级解霸截取视频中的单帧图像 B、用数码相机拍摄的风景照片 C、用Windows附件中的画图程序绘制的圆 D、用Flash软件中的“椭圆工具”在舞台上绘制的圆
-
4、通过以下操作获得的图片,属于矢量图形的是( )A、Word中的自选图形 B、用附件中的画图程序绘制的图形 C、用Photoshop软件绘制的图形 D、用数码相机拍摄的照片
-
5、小张绘制了一幅背景图,放大后出现了边缘锯齿状的模糊,他使用的绘图软件可能是( )A、CorelDraw B、Flash C、AutoCAD D、Photoshop
-
6、使用Photoshop 软件对“夏日印象.psd”进行处理,编辑界面如图所示,以下描述不正确的是( )
 A、右击“荷花”图层选择“复制图层”命令后可以得到该图层的副本 B、选中“荷花”图层后使用“自由变换”命令可以旋转、缩放荷花 C、将“夏日印象.psd”另存为“夏日印象.jpg”后可以看到荷叶的投影和外发光效果 D、交换“荷叶”图层和“荷花”图层的顺序,不影响作品的呈现效果
A、右击“荷花”图层选择“复制图层”命令后可以得到该图层的副本 B、选中“荷花”图层后使用“自由变换”命令可以旋转、缩放荷花 C、将“夏日印象.psd”另存为“夏日印象.jpg”后可以看到荷叶的投影和外发光效果 D、交换“荷叶”图层和“荷花”图层的顺序,不影响作品的呈现效果 -
7、使用Photoshop软件对某多媒体文档进行处理,其部分编辑界面如图所示,下列说法正确的是( )
 A、可以将“背景”图层的不透明度修改为50% B、可以直接为“相册”图层添加“镜头光晕”滤镜效果 C、可以通过拷贝图层样式的方法将“相册”图层的样式应用到“大照片”图层 D、如果将该文件的格式保存为bmp格式仍然可以看到“点缀”图层中的内容
A、可以将“背景”图层的不透明度修改为50% B、可以直接为“相册”图层添加“镜头光晕”滤镜效果 C、可以通过拷贝图层样式的方法将“相册”图层的样式应用到“大照片”图层 D、如果将该文件的格式保存为bmp格式仍然可以看到“点缀”图层中的内容 -
8、使用Photoshop软件编辑“雨中莲花.psd”文件,如图所示。复制“柳树.jpg”中的柳树图像后,选中“雨中莲花.psd”文件中的“荷叶”图层,执行“粘贴”命令,则柳树图像将出现在( )
 A、“远景”图层 B、“荷叶”图层 C、“雨中莲花”图层 D、“图层1”图层
A、“远景”图层 B、“荷叶”图层 C、“雨中莲花”图层 D、“图层1”图层 -
9、小方同学在Photoshop软件中编辑某作品,其部分界面如图所示

以下说法正确的是( )
A、当前处理的文件属于位图文件 B、“鹰击长空”图层属于文字图层 C、将该文件存储为JPG格式,“鹰击长空”图层内容不会丢失 D、可以使用魔棒工具精确选取背景图层中的雄鹰图像部分 -
10、使用Photoshop软件制作某作品,部分界面如图所示。下列说法正确的是( )
 A、“文字”图层中设置的图层样式均可见 B、“背景”图层下方不可能还有其他图层 C、该位图文件中每个像素采用8位二进制保存 D、可以使用油漆桶工具修改“文字”图层中的文字颜色
A、“文字”图层中设置的图层样式均可见 B、“背景”图层下方不可能还有其他图层 C、该位图文件中每个像素采用8位二进制保存 D、可以使用油漆桶工具修改“文字”图层中的文字颜色 -
11、在Photoshop软件中,对“photo.psd”文件进行下列操作,可能导致该图像文件图层数量减少的操作是( )A、选中“photo.psd”文件中的第一个图层,执行“向下合并图层”操作 B、用移动工具将“春.jpg”文件中的图像拖到“photo.psd"文件中 C、对“photo.psd”文件中某个图层设置滤镜效果 D、对“photo.psd"文件中某个图层设置图层样式
-
12、使用Photoshop 软件对“亚里士多德.psd"进行处理,编辑界面如下图所示:

则下列描述不正确的是( )
A、“人物”图层设置了不透明效果 B、可利用“T”工具,修改“文字”图层的文字内容 C、“文字”图层设置了2个图层样式,但起作用的只有1个 D、若将此文件保存为png格式,则“背景”图层内容仍旧可见 -
13、使用PhotoShop软件制作“旅行”作品,部分界面如图所示。下列说法不正确的是( )
 A、拷贝“文字内容”的图层样式到“旅行”图层,则“旅行”图层的样式包含“外发光” B、“背景”图层可以设置滤镜效果 C、“船”图层的内容不可见是由于该图层被隐藏 D、将作品存储为JPEG格式文件,“船”图层中的内容不可见
A、拷贝“文字内容”的图层样式到“旅行”图层,则“旅行”图层的样式包含“外发光” B、“背景”图层可以设置滤镜效果 C、“船”图层的内容不可见是由于该图层被隐藏 D、将作品存储为JPEG格式文件,“船”图层中的内容不可见 -
14、小明正在使用Photoshop软件制作“寻宝之旅”的作品,部分界面如图所示。

下列说法正确的是( )
A、可用文本工具修改“寻宝之旅”图层中文字的字体 B、使用“图像大小”命令调整“宝藏”图层中图像的大小,不会影响其他图层中的内容大小 C、可对“藏宝图”图层直接设置滤镜效果 D、可对“背景”图层直接设置图层样式 -
15、小马使用PhotoShop软件制作“安全游泳”宣传照,部分界面如图所示,下列说法正确的是( )
 A、当前状态下,执行“拷贝”“粘贴”命令后,“安全游泳”会出现在新图层中 B、复制“男孩”图层的图层样式,粘贴到背景图层,背景图层显示外发光、内发光的效果 C、选中“安全游泳”图层,添加“波浪”的滤镜,滤镜效果只呈现在矩形选框内 D、将“女孩”图层移动到“男孩”图层的下方,矩形选框选中的内容不变
A、当前状态下,执行“拷贝”“粘贴”命令后,“安全游泳”会出现在新图层中 B、复制“男孩”图层的图层样式,粘贴到背景图层,背景图层显示外发光、内发光的效果 C、选中“安全游泳”图层,添加“波浪”的滤镜,滤镜效果只呈现在矩形选框内 D、将“女孩”图层移动到“男孩”图层的下方,矩形选框选中的内容不变 -
16、用Photoshop软件制作“在线教育”作品。当前状态下,下列说法正确的是( )
 A、可以修改“平台”图层名为“直播机构” B、“资源”图层内容不可见的原因是被其他图层遮挡 C、“标题”图层设置了“波纹"滤镜效果 D、可以把“标题”图层的图层样式复制到“背景”图层
A、可以修改“平台”图层名为“直播机构” B、“资源”图层内容不可见的原因是被其他图层遮挡 C、“标题”图层设置了“波纹"滤镜效果 D、可以把“标题”图层的图层样式复制到“背景”图层 -
17、使用Photoshop制作“古诗”的部分界面如下图所示,下列说法正确的是( )
 A、“江南春”图层添加了滤镜效果 B、“船”图层中只能看到一种图层效果 C、“古诗”图层中的文字可以用文本工具直接修改 D、“鸟”图层已被锁定,因此将无法修改该图层的名称
A、“江南春”图层添加了滤镜效果 B、“船”图层中只能看到一种图层效果 C、“古诗”图层中的文字可以用文本工具直接修改 D、“鸟”图层已被锁定,因此将无法修改该图层的名称 -
18、既可以存储静态图像,又可以存储动画的图像文件格式是( )A、BMP B、GIF C、TIF D、JPEG
-
19、一段未经压缩的视频参数为:每帧画面为640×480像素、16位色,若每秒钟视频数据量为14.6MB,则每秒钟播放的帧数大约为( )A、12 B、25 C、50 D、100
-
20、小王同学利用音频处理软件编辑音频文件“伴奏.wav”,界面如图所示,在当前状态下依次进行操作:①增加前10秒音频音量2dB②删除③插入5秒的静音④以原参数保存音频文件,则处理后的音频文件的存储容量约为( )
 A、28MB B、31.2MB C、32.8MB D、36.2MB
A、28MB B、31.2MB C、32.8MB D、36.2MB