相关试卷
-
1、有如下Python程序段:
from random import randint
from math import sqrt
a=[0,0,0,0,0]
for i in range(5):
a[i]=randint(1,5)*2
n=0
while n<5:
for i in range(4,n,-1):
if a[i]<a[i-1] and int(sqrt(a[i]))!=sqrt(a[i]):
a[i],a[i-1]=a[i-1],a[i]
n+=1
print(a)
运行该程序段,输出的结果不可能是( )
A、[2,8,10,10,4] B、[6,8,10,4,10] C、[2,4,8,10,10] D、[6,8,6,4,8] -
2、某二叉树先序遍历为“chapter2”,中序遍历为“ahpcetr2”则其后序遍历为“( )”A、2retpahc B、ahctr2pe C、aphe2rtc D、无法确定
-
3、电梯可以检测到是否有人进出,从而准确地控制电梯门是否关闭到位,是因为电梯安装了( )A、红外传感器和位置传感器 B、红外传感器和指纹传感器 C、距离传感器和温度传感器 D、压敏传感器和声音传感器
-
4、如图所示是某算法的部分流程图,下列说法正确的是( )
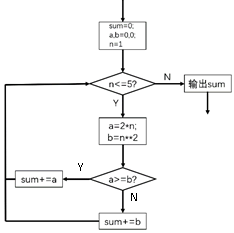 A、流程执行后,sum的值是64 B、语句“sum+=b”被执行了3次 C、该部分算法采用顺序结构 D、语句“sum+=a”被执行了3次
A、流程执行后,sum的值是64 B、语句“sum+=b”被执行了3次 C、该部分算法采用顺序结构 D、语句“sum+=a”被执行了3次 -
5、下列事例可以体现信息系统“对外部环境有依赖性”的是( )A、2013年,光大证券因为订单生成系统存在的缺陷,在2秒内瞬间重复生成26082笔预期外的市价委托订单,单日损失约为1.94亿元人民币 B、2003年8月14日,美国东北部、中西部8个州和加拿大安大略省发生史上最大规模的停电事故,造成250亿~300亿美元的损失。 C、2014年8月2日凌晨,一款名为“XX神器”的恶意手机病毒在全国范围内爆发式传播,一天之内群发500万条诈骗短信,造成所有中招手机用户共计50万元的话费损失 D、2014年12月25日,大量12306网站用户数据在网络上疯狂传播,被泄露的数据达131653条,包括用户账号、明文密码、身份证号码和邮箱等多种信息。
-
6、小明制作了一段时长为60秒的视频,采用NTSC制式,每帧图像像素为1024*768,颜色位深度为8。则该视频存储容量约为( ).A、169MB B、84MB C、536MB D、1350MB
-
7、下列说法中,不正确的一项是( )A、Excel软件中对A114:A514单元格进行求和,可以键入公式=SUM(A114:A514) B、大数据可以分为对静态数据的批处理、对流数据的实时计算和对图片文件的图计算 C、MapReduce的核心处理思想是将任务分解并分发到多个节点上进行处理,最后汇总输出 D、要展现数据的比例关系,可视化时可以采用饼图或环形图等
-
8、关于下列四幅图,说法不正确的一项是( )
 A、图a为人工智能学科结构示意图,说明人工智能是一门多学科广泛交叉的前沿科学 B、图b为图灵机模型,图灵机是现代计算机的理论模型 C、图c为多层神经网络,这是一种典型的深度学习模型 D、图d为达·芬奇外科手术机器人,为混合增强智能,人工智能是智能回路的总开关
A、图a为人工智能学科结构示意图,说明人工智能是一门多学科广泛交叉的前沿科学 B、图b为图灵机模型,图灵机是现代计算机的理论模型 C、图c为多层神经网络,这是一种典型的深度学习模型 D、图d为达·芬奇外科手术机器人,为混合增强智能,人工智能是智能回路的总开关 -
9、以下哪些是常用的信息系统安全风险防范技术? ( )A、图像处理技术 B、加密技术 C、认证技术 D、恶意代码检测与防范技术
-
10、现代通信技术主要指以电磁波、声波、光波的方式,把信息通过电脉冲从发送端(信源)传输到一个或多个接收端(信宿)的一系列技术,通常包括( )。A、无线接入技术 B、数字通信技术 C、信息传输技术 D、光纤接入技术
-
11、下列属于人工智能应用的是( )。A、在使用导航软件时,用拼音输入法输入目的地 B、株洲博物馆利用摄像头通过人脸识别技术采集观众的参观轨迹,分析观众行为 C、为了保证乘坐电梯人员的健康,使用语音控制电梯的运行 D、在出国旅行时使用多国语言翻译机,与其他国家人员进行交流
-
12、以下正确的逻辑常量是( )A、true B、false C、True D、False
-
13、随着技术的发展,数据采集的手段日益丰富。下列属于数据采集的是( )A、疫情防控专用通道测体温 B、汽车尾气检测系统获取实时数据汽车尾气检测系统获取实时数据 C、用手机播放音乐 D、潜水器潜入海底进行取样,提取样本特征
-
14、小王在网上购买了—套衣服,店家提出直接汇款到他的银行账户,这样就能打9折,小王依言而行。( )
-
15、3D技术发展迅速,它包括3D设计、3D打印、3D显示等一系列3D产业技术。( )
-
16、人工智能一定程序上能模仿人类的活动。( )
-
17、有逻辑错误的程序在运行时会有语法错误提示。( )
-
18、计算机低级语言的学习难,运行效率也低,因此目前已完全淘汰。( )
-
19、利用网络爬虫获取研究性学习所需要的数据,是采用了网络数据采集法。( )
-
20、小军要完成对中学生心理健康状态的调查,他可以使用问卷星提供的问卷设计、调查回收、结果分析来完成。( )