相关试卷
- 浙江省七彩阳光新高考研究联盟2025-2026学年高二上学期期中联考技术试题-高中信息技术
- 浙江省台州市十校联盟2025-2026学年高二上学期期考试技术试题-高中信息技术
- 重庆市黔江实验中学2025-2026学年高三上学期期中信息技术试题
- 云南省玉溪一中2024-2025学年上学期期末学业水平合格性考试模拟卷信息技术试卷
- 贵州省贵阳市2024-2025学年高一下学期7月期末信息技术试题
- 江苏省南通市2024-2025学年高一上学期1月期末信息技术试题
- 四川省内江市2024-2025学年高一下学期期末检测题技术试卷
- 上海市浦东新区上海师范大学附属中学2024-2025学年高一上学期10月期中信息技术试题
- 海南省临高县第二中学2024-2025学年高一上学期期中考试信息技术试题
- 江苏省徐州市2024-2025学年高一下学期期末抽测信息技术试题
-
1、算法的特征包括有穷性、确切性、输入、输出、可行性。 ( )
-
2、判断输入的一个三位正整数是否为“水仙花数”,是则输出“YES”,不是则输出“NO”。(注:“水仙花数”是指一个三位正整数,它各位数字的立方之和等于它本身)。画流程图并写出VB程序。
-
3、已知正方形的边长为x,画出求下图阴影部分面积的流程图,并写出VB程序。(π取3.14)
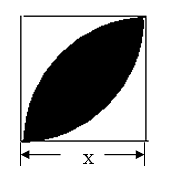
-
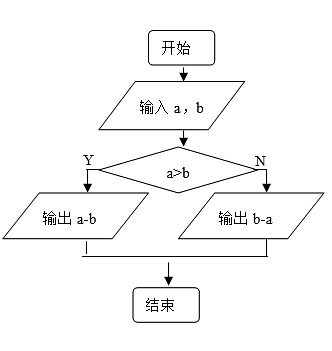
4、流程图的功能是输入三个数,输出其中数。

-
5、若输入的值是100,输出结果是。

-
6、运行结果是。

-
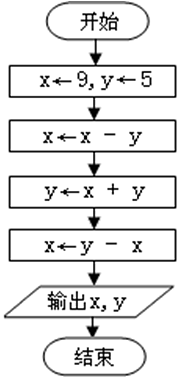
7、流程图的执行结果是。
-
8、流程图的执行结果是。

-
9、流程图的执行结果是。

-
10、流程图的执行结果是。
-
11、下边是根据购买量w计算应付价格price的流程图,填写(1)、(2)
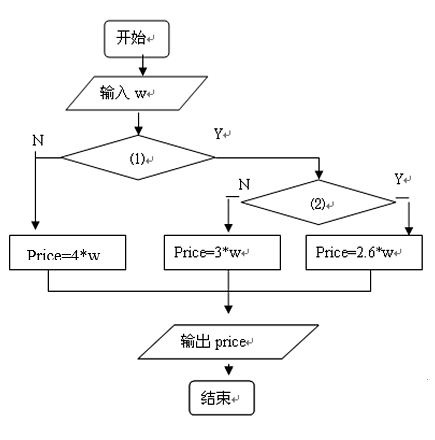
香蕉促销价
购买量
单价(元/千克)
3以下
4
3——6(含3千克)
3
6以上(含6千克)
2.6
-
12、在下列流程图中输入一个大于10的整数N时,输出结果为此整数的十位上的数码

在流程图空白框处应该填入。
-
13、假设圆半径为r,p=3.14,圆面积为s,计算圆面积的流程图如下:

在流程图空白框处应该填入。
-
14、将数学表达式 写成VB语言的表达式是。
-
15、逻辑表达式SIN(1) >= 16/19 AND 4 mod 2 = 2 mod 4(说明:SIN(x)是正弦函数sin x)的值是。(填F或T)
-
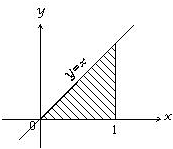
16、写出如图平面直角坐标系中阴影区域(包括边界)对应的逻辑表达式。
-
17、某CD格式的音频文件,其采样频率为8kHz,16位,立体声双声道,此音频采样过程中每秒的数据量是字节。
-
18、将英文字母转化为ASCII码的过程,是一个信息的化过程。
-
19、因特网上一个B类地址所在的网络,其可分配的IP地址共有个。
-
20、已知M进制数(321)M中的数码3所表示的数值大小为十进制的48,则M是。