相关试卷
- 浙江省七彩阳光新高考研究联盟2025-2026学年高二上学期期中联考技术试题-高中信息技术
- 浙江省台州市十校联盟2025-2026学年高二上学期期考试技术试题-高中信息技术
- 重庆市黔江实验中学2025-2026学年高三上学期期中信息技术试题
- 云南省玉溪一中2024-2025学年上学期期末学业水平合格性考试模拟卷信息技术试卷
- 贵州省贵阳市2024-2025学年高一下学期7月期末信息技术试题
- 江苏省南通市2024-2025学年高一上学期1月期末信息技术试题
- 四川省内江市2024-2025学年高一下学期期末检测题技术试卷
- 上海市浦东新区上海师范大学附属中学2024-2025学年高一上学期10月期中信息技术试题
- 海南省临高县第二中学2024-2025学年高一上学期期中考试信息技术试题
- 江苏省徐州市2024-2025学年高一下学期期末抽测信息技术试题
-
1、小明在登录平安银行网银时需要输入手机短信验证码,他收到的短信内容为“尊敬的客户,您正在补充手机号码,请输入手机验证码:795812,有效期:2分钟。【中国平安】”。他在接到验证码2分钟后输入,系统提示验证码失效,这主要体现了信息的( )。A、时效性 B、可以加工和处理的 C、共享性 D、载体依附性
-
2、下列选项中,正确的做法是( )A、购买盗版的杀毒软件,并放置在网上提供给其他网民使用 B、引用他人的作品时,需注明所引用信息的出处 C、破解别人密码,私自删除他人计算机内重要数据 D、利用软件破解别人的无线路由器密码,免费上网
-
3、案例:
小林接到一条短信称“我的手机和银行卡都丢了,现在我用同学的手机给您发短信,请速汇1000元钱到我同学的银行卡上,卡号为*********”。小李说:“这是一条欺诈信息,因为这条信息没有发信人的落款,不可信”。小明说:“既然发信人知道了小林的手机号码,说明是熟悉的人,可以相信”。你觉得他们说的对吗?( )
A、小李和小明说的都对 B、小李和小明说的都不对 C、小李说的对 D、小明说的对 -
4、数字升序排序是按从最小的负数到最大的正数进行排序。( )A、正确 B、错误
-
5、小玲要为自己的电子邮箱设置登录密码,下列选项中安全性最高的密码是( )。A、xiaoling B、ling2007 C、L#3y9m8z D、12345678
-
6、信息处理进入了计算机世界,实质上是进入了( )的世界。A、模拟数字 B、十进制数 C、二进制数 D、抽象数字
-
7、算法的每一个步骤可以对应程序中一条或多条语句,每条语句最多只能实现一个操作。( )
-
8、顺序结构的执行顺序是自下而上。( )
-
9、若输入16和12,输出结果是( )。
 A、0 B、1 C、4 D、12
A、0 B、1 C、4 D、12 -
10、某算法的部分流程图如图所示,执行这部分流程,若输入x的值依次为10,7,8,12,0,则输出k的值是( )
 A、2 B、3 C、4 D、5
A、2 B、3 C、4 D、5 -
11、如图展示了我国近十年的GDP。为了直观地显示GDP的变化趋势,可以使用( )进行的数据可视化。
 A、柱形图 B、折线图 C、饼图 D、雷达图
A、柱形图 B、折线图 C、饼图 D、雷达图 -
12、下列流程图中是循环结构的是( )
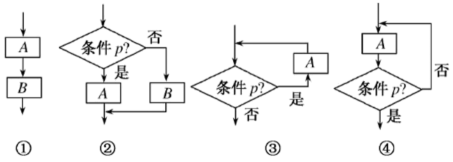 A、①② B、②③ C、③④ D、②④
A、①② B、②③ C、③④ D、②④ -
13、春晚《闪耀时刻》节目中虚拟歌手第一人洛天依的演出运用的是( )技术。A、VR B、全息投影 C、CR D、3D技术
-
14、十进制数-48的反码为 ( )A、10011000 B、10110000 C、11001111 D、10100000
-
15、下列不属于算法基本特点的是( )。A、有穷性 B、有一个或多个输入 C、可行性 D、有一个或多个输出
-
16、已知英文小写字母“a”的 ASCII 码十进制数是 97,则小写字母“b”的 ASCII 码在计算机内存储方式正确的是( )。A、11100010 B、01100001 C、1100010 D、01100010
-
17、下列关于算法的基本结构说法错误的是( )A、顺序结构中的每个步骤一定会被执行一次,而且仅被执行一次 B、对于分支结构来说,必定有一个分支被执行,其它的分支则被忽略 C、算法的基本结构分顺序结构、分支结构和循环结构三种 D、循环结构中的步骤必定会被执行一次
-
18、以下关于大数据处理的说法,错误的是( )A、气象部门收集过去10年的气象数据,分析气候变化情况,属于批处理计算 B、导航软件根据用户手机实时定位数据,分析路况并调整路线,属于流计算 C、点餐平台的数据中包含了多种不同菜品的售价,体现大数据的数据类型多 D、交警处理事故纠纷时,从大量监控中找寻几秒有关画面,体现大数据的价值密度低
-
19、在求一元二次方程实数根的算法中,当方程不存在实数根,也要输出“方程无实数根”,这一要求主要体现了算法特征中的( )A、有穷性 B、确定性 C、有1个或多个输出 D、有0个或多个输出
-
20、2021年是十四五规划开局之年,我国经过多年努力奋斗,在各个方面取得了巨大的成就,十四五规划文本的词云图如下,下列说法正确的是( )
 A、词云图必须显示该数据集合包含的全部词语 B、通过词云图显示,词语“十四五”比“征程”的出现频率高 C、最能表现文本特征的词有“发展”“新起点”“实现” D、词云图只能通过文字的大小来表示关键词的重要程度
A、词云图必须显示该数据集合包含的全部词语 B、通过词云图显示,词语“十四五”比“征程”的出现频率高 C、最能表现文本特征的词有“发展”“新起点”“实现” D、词云图只能通过文字的大小来表示关键词的重要程度