相关试卷
-
1、有数组a,其奇数下标的元素是降序排序的奇数,偶数下标的元素是降序排序的偶数,依据对分查找思想,设计一个在数组a中查找数据key的程序。部分程序段如下:
Key = Val(Text1.Text)
i = 1: j = 10: flag = False
Do While

m = Int((i + j) / 2 + 0.5)
If
 Then m = m - 1
Then m = m - 1If a(m) = Key Then
flag = True
ElseIf
 Then
Theni = m + 2
Else
j = m - 2
End If
Loop
If Not flag Then
Text2.Text = "查无数据"
Else
Text2.Text = "该数位置为" + Str(m)
End If
方框①②③中的代码依次为( )
A、①i <= j And Not flag ②Key Mod 2 + a(m) Mod 2 = 1 ③a(m) > Key B、①i <= j And Not flag ②Key Mod 2 <> a(m) Mod 2 ③a(m) < Key C、①i <= j Or Not flag ②Key Mod 2 + a(m) Mod 2 = 1 ③a(m) > Key D、①i <= j Or Not flag ②Key Mod 2 <> a(m) Mod 2 ③a(m) < Key -
2、有VB程序段如下:
p = Val(Text1.Text)
t = 0: j = 2: flag = True
s = Text1.Text + "="
Do While p > 1 And flag
If p Mod j = 0 Then
t = t + 1
p = p \ j
s = s + Str(j) + "*"
Else
If t = 1 Then flag = False
t = 0: j = j + 1
End If
If p = 1 And t = 1 Then flag = False
Loop
If flag Then
Text2.Text = Mid(s, 1, Len(s) - 1)
Else
Text2.Text = Text1.Text + "不是漂亮数"
End If
执行该程序段,在文本框Text1中输入6,则文本框Text2中显示的内容为( )
A、6= 2* 3 B、6= 2* 3* C、6= 1* 2* 3 D、6不是漂亮数 -
3、有VB程序段如下:
s1 = Text1.Text
s2 = ""
For i = 1 To Len(s1)
c = Mid(s1, i, 1)
If c >= "0" And c <= "9" Then
c = Chr((Asc(c) - Asc("0") + 1) Mod 10 + Asc("0"))
s2 = s2 + c
ElseIf c >= "A" And c <= "Z" Then
c = Chr(Asc(c) + 32)
s2 = c + s2
End If
Next i
Text2.Text = s2
执行该程序段,在文本框Text1中输入“GoLand,19”,则文本框Text2中显示的内容为( )
A、lg20 B、lg210 C、210,dnalog D、210,goland -
4、已知k为十进制多位整数,与语句“If k \ 10 Mod 2 = 0 Then a = 1 Else a = 2”功能不同的是( )A、If k \ 10 Mod 2 = 1 Then a = 2 Else a = 1 B、If k Mod 100 \ 10 Mod 2 = 0 Then a = 1 Else a = 2 C、a = 2 : If k \ 10 Mod 2 = 0 Then a = 1 D、a = 2 : If (k Mod 100) \ 10 Mod 2 = 0 Then a = 1
-
5、某算法的部分流程图如图所示。执行这部分流程,输入n的值为4,则输出值不可能的是( )
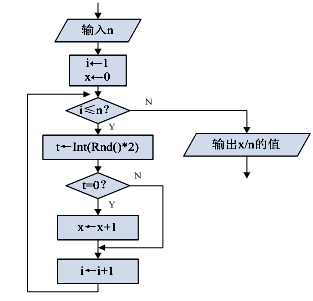 A、0 B、0.5 C、0.8 D、1
A、0 B、0.5 C、0.8 D、1 -
6、下列VB表达式正确的是( )A、a + |c| B、a1 + 2 C、3a - 1 D、2 × h / g
-
7、一段时长为40秒、像素为1024*768,采用PAL制式(25帧/秒)且未经压缩的无声视频,以压缩比10:1转换为容量为75MB的MPG文件,则原始视频的颜色模式可能是( )A、16色彩色 B、16位彩色 C、24位真彩色 D、256级灰度
-
8、使用Photoshop软件制作“我的读书梦”作品,部分界面如图所示。

下列说法正确的是( )
A、可以使用文本工具修改“我的读书梦”图层中的文字字体 B、不能直接为“书香中国”图层设置“波浪”滤镜效果 C、在当前状态下执行“剪裁”操作,不会影响“背景”图层内容的呈现效果 D、拷贝“书香中国”图层样式到“我的读书梦”图层,可以保留“我的读书梦”图层的投影效果 -
9、某加密算法如下:
1)以字节为单位对ASCII字符进行加密处理;
2)8位二进制数最高位不处理;
3)后7位做如下处理:先按位取反,再右移3位,最高位用右移出的最低位填充;
所得的8位二进制数即为密文的编码。已知某字符的密文为“i”,其对应的原文字符是( )
 A、b B、u C、1 D、2
A、b B、u C、1 D、2 -
10、使用Access软件创建“jsxxb”数据表,其设计视图的部分界面如图所示。
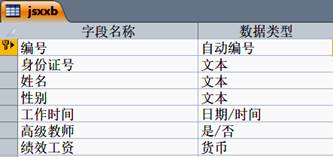
下列说法正确的是( )
A、若将某个字段设置为主键,其数据类型必须为自动编号 B、将数据表导出到Excel,“高级教师”字段值将变为“是/否”字样 C、可以直接输入数字如“3000”作为“绩效工资”字段值 D、在当前状态下删除一行,将导致该数据表的记录数减少 -
11、下列有关网页与浏览器的说法,不正确的是( )A、使用不同的搜索引擎对相同关键词进行检索,得到的结果可能不同 B、用HTML(超文本标记语言)可以描述网页中的文本、图像和超链接等元素 C、在IE浏览器中,使用“添加到收藏夹”功能可以保存正在浏览的网页内容 D、在IE浏览器中,以“文本文件(*.txt)”类型保存网页,不能保存网页中的超链接地址
-
12、微信中有语音转文字功能,以下说法正确的是( )A、语音和文字是信息,而微信是载体 B、微信属于信息表达方式,语音和文字属于信息表达技术 C、该功能主要采用了虚拟现实技术 D、该过程反映了信息具有可加工处理性
-
13、使用Flash软件创作“小燕子的春天”多媒体作品,如图所示,各个图层内容与图层名称相对应。请回答下列问题:
 (1)、当前编辑的场景名为。(2)、图中“小燕子”图层第1帧到第40帧实现了“小燕子”从舞台左侧向舞台右侧飞行的效果,该动画类型是(选填,填字母:A .逐帧动画 / B .形状补间动画 / C .动画补间动画)。(3)、为使“柳叶”图层内容在该场景播放1秒钟后出现,在不影响其他动画效果的前提下,正确的操作是。(4)、图中“文字”图层第11帧到第30帧的动画实现了文字实例从完全透明到完全显示的效果,第11帧中“文字”实例的Alpha值是。(5)、库中的音频素材时长为10秒,应用于“music”图层中,测试场景时,要使该场景播放一遍结束时“music”图层中的声音继续播放,可将其声音“同步”属性设置为(选填:事件/数据流)。(6)、测试影片时,单击当前场景中的“play”按钮,停止所有声音播放,并使影片跳转到“片尾”场景第1帧并开始播放,则“播放”按钮的动作脚本为on(release){}。
(1)、当前编辑的场景名为。(2)、图中“小燕子”图层第1帧到第40帧实现了“小燕子”从舞台左侧向舞台右侧飞行的效果,该动画类型是(选填,填字母:A .逐帧动画 / B .形状补间动画 / C .动画补间动画)。(3)、为使“柳叶”图层内容在该场景播放1秒钟后出现,在不影响其他动画效果的前提下,正确的操作是。(4)、图中“文字”图层第11帧到第30帧的动画实现了文字实例从完全透明到完全显示的效果,第11帧中“文字”实例的Alpha值是。(5)、库中的音频素材时长为10秒,应用于“music”图层中,测试场景时,要使该场景播放一遍结束时“music”图层中的声音继续播放,可将其声音“同步”属性设置为(选填:事件/数据流)。(6)、测试影片时,单击当前场景中的“play”按钮,停止所有声音播放,并使影片跳转到“片尾”场景第1帧并开始播放,则“播放”按钮的动作脚本为on(release){}。 -
14、使用Photoshop 软件制作“快乐阅读”作品,部分界面如下图所示。
 (1)、图中A处的图标表示该图层设置了(选填,填字母:A .图层样式/B .蒙板/C .不透明度/D .函数)。(2)、将当前作品以JPEG格式保存,保存后的图像文件中“女孩”图层内容(选填:可视 / 不可视)。(3)、选中相应图层后,能直接添加滤镜的图层有个(填数字)。(4)、选中“男孩”图层,可以直接执行的操作有 (可多选,选字母)A、移动“男孩”图层至“女孩”图层上方 B、修改“男孩”图层名称 C、删除“男孩”图层 D、将“男孩”水平翻转
(1)、图中A处的图标表示该图层设置了(选填,填字母:A .图层样式/B .蒙板/C .不透明度/D .函数)。(2)、将当前作品以JPEG格式保存,保存后的图像文件中“女孩”图层内容(选填:可视 / 不可视)。(3)、选中相应图层后,能直接添加滤镜的图层有个(填数字)。(4)、选中“男孩”图层,可以直接执行的操作有 (可多选,选字母)A、移动“男孩”图层至“女孩”图层上方 B、修改“男孩”图层名称 C、删除“男孩”图层 D、将“男孩”水平翻转 -
15、小华收集了2012-2018年浙江省各市水资源总量的相关数据,并使用Excel软件进行了数据处理,界面如图a所示,请回答下列问题:

图a
(1)、区域B14:H14的数据是通过公式计算得到的,在B14单元格输入公式时应用了AVERAGE函数,并用自动填充功能完成区域C14:H14的计算,则B14单元格中的公式是。(2)、若要对各个城市的数据以“2018年”为关键字按降序进行排序,则排序时选择的数据区域是(单选,填字母:A .H2:H13 / B .A1:H14 / C .A2:H14 / D .A2:H13)。(3)、根据图a中数据制作的图表如图b所示,创建该图表的数据区域是。
图b
(4)、将区域A2:H13的数据复制到新工作表并进行筛选,设置“城市”和“2018年”的筛选方式如图c所示,则筛选出的城市数有个(填数字)。
-
16、小华登录邮箱,写信编辑的部分界面如图所示。
 (1)、发送成功后,共有(填数字)个用户收到该邮件。(2)、邮箱账号为469002980@qq.com的用户从电子邮件服务器中将邮件读到本地计算机的过程中使用的协议为(选填:HTTP / POP3 / SMTP )。(3)、附件“1.jpg”文件采用的是(选填:无 / 无损 / 有损)压缩格式。(4)、邮件中所使用的文字、图像等是常用的信息表达(选填:方式 / 技术)。
(1)、发送成功后,共有(填数字)个用户收到该邮件。(2)、邮箱账号为469002980@qq.com的用户从电子邮件服务器中将邮件读到本地计算机的过程中使用的协议为(选填:HTTP / POP3 / SMTP )。(3)、附件“1.jpg”文件采用的是(选填:无 / 无损 / 有损)压缩格式。(4)、邮件中所使用的文字、图像等是常用的信息表达(选填:方式 / 技术)。 -
17、使用Word软件编辑某文档,部分界面如图所示。

请回答下列问题:
(1)、实现图中的图文环绕效果可以采用(选填:嵌入型 / 四周型 / 紧密型 /上下型)环绕方式。(2)、文中共有(填数字)处批注,批注用户有(填数字)个。(3)、下列说法中正确的是 (可多选,填字母)A、删除批注内容“简称马拉松”,批注对象不会被删除 B、执行“接受对文档的所有修订”,文字“提起”被修改为“提及” C、执行“拒绝对文档的所有修订”,最后一行内容为“即指全程马拉松” D、执行“拒绝对文档的所有修订”,最后一行内容为“既指全程马拉松” -
18、用Flash 软件制作动画作品,其中一个场景的部分时间轴界面如图所示。

下列说法正确的是( )
A、“声音”图层被隐藏,故测试场景时该图层中的声音不会播放 B、“按钮”图层第40帧上的“ɑ”标记表明该帧内的按钮上设置有动作脚本 C、“动画”图层第21帧插入关键帧,将改变该图层的补间动画效果 D、测试场景时,“背景”图层中的背景画面内容可能发生变化 -
19、一段时长为40秒、1024×768像素、24位真彩色、PAL制式(25帧/秒)的未经压缩AVI格式无声视频,其文件存储容量约为( )A、23MB B、70 MB C、703 MB D、2250 MB
-
20、关于数据冗余和数据压缩,下列说法正确的是( )A、某些图像从区域上看存在较强的纹理结构,这属于空间冗余 B、视频前一帧图像与后一帧图像之间存在较大的相关性,这属于视觉冗余 C、多媒体数据压缩之后与压缩之前相比较,往往质量更高 D、用WinRAR把整个文件夹中的所有内容压缩成RAR文件,这属于无损压缩