-
1、下列对算法描述方法的表述正确的是( )A、算法只能用自然语言来描述 B、算法只能用流程图来表示 C、描述算法可以有多种方法 D、用流程图描述算法,通常是我们理解算法的第一步
-
2、为了响应“光盘行动”的号召,学校食堂要开发一款订餐APP,制订了如下工作你认为流程最恰当的一项是( )A、分析问题、设计算法、编写程序、调试与维护 B、设计算法、编写程序、分析问题、调试与维护 C、分析问题、编写程序、调试与维护、设计算法 D、编写程序、调试与维护、分析问题、设计算法
-
3、大部分社交软件都有好友推荐的功能,当用户A和用户B的共同好友数量超过阀值p时,由系统向用户A推荐用户B。其中共同好友判定方法为:用户A和用户B不是好友,用户C分别是用户A和用户B的好友,则共同好友数量加1。编写Python程序,实现好友推荐功能。运行程序,首先从文件中读取用户id及好友列表后,处理后显示用户之间的关系;再输入推荐目标用户id和阈值p;最后显示向目标用户推荐的好友列表。
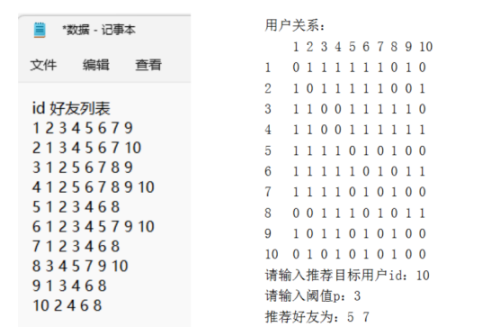 (1)、根据如图所示数据,若输入推荐目标用户id为“1”,输入阈值为“4”,则推荐好友为:。(2)、主程序,读取“数据.txt”文件,进行处理后显示用户关系二维表,再输入推荐目标用户id和阈值p,显示向目标用户推荐的好友列表,请在划线处填入合适的代码。
(1)、根据如图所示数据,若输入推荐目标用户id为“1”,输入阈值为“4”,则推荐好友为:。(2)、主程序,读取“数据.txt”文件,进行处理后显示用户关系二维表,再输入推荐目标用户id和阈值p,显示向目标用户推荐的好友列表,请在划线处填入合适的代码。n= 10
sj= ];zj= [];j= 0]
#按行读取"数据.txt"文件,每次读一行文字存入字符串变量line 中
f=open("数据txt")
line=f.readline( ) #读取标题行
line= =f.readline( )
while line:
sj.append(line.split(" ")) #将字符串以""为间隔分割成多个字符串组成的列表
line=f.readline( ) #读取下一行
zj = zhengli(sj)
#显示各用户之间关系二维表,代码略
#输入推荐目标用户id和阈值p,显示向目标用户推荐的好友列表
id = int(input("请输入推荐目标用户id: "))
p = int(input("请输入阈值p: "))
#调用函数进行好友推荐
if len(j) != 0:
t=0
print("推荐好友为:",end = "")
while t < len(tj):
print(j[t, end ="")
t=t+ 1
else:
print("没有推荐好友")
(3)、编写整理数据函数zhengli,根据好友列表,生产关系二维表,请在划线处填入合适的代码。def zhengli(sj):
r= [[0 for i in range(n)]for j in range(n)]
for i in range(n): .
for j in sj [i][l:]:
r[i][nt(j)-1]= 1
return r
(4)、编写函数fenxi,根据输入推荐目标用户id和阈值p,显示向目标用户推荐的好友列表,请在划线处填入合适的代码。def fenxi(id,p):
res =[]
for i in range(n):
c=0
for j in range(n):
if i!=id-1 and j!= id-1 and i!=j:
if
c+= 1
if
res.append(i+1)
return res
-
4、分组冒泡排序。分别对数组a的奇数和偶数位置的元素进行冒泡排序,即采用“跳跃式冒泡”的方法,每次跳跃的步长为2,将数组分成2个子序列,分别对这2个子序列进行排序。例如,对数组a=[6,3,5,4,1,2,8,7]进行分组跳跃式升序冒泡排序,排序后的数组a=[1,2,5,3,6,4,8,7]。(1)、对数组a=[4,5,2,9,6,7,10,3,8,1]进行分组跳跃式升序冒泡排序,则排序后的数组(2)、实现上述功能的Python程序如下,请在划线处填入合适的代码。
import random
n=8
a=[random.randint(1 ,9) for i in range(n)]
for i in range(0,n,)
forj in range()
if a[j]<a[j-2]:
a[j],a[j-2]=a[j-2],a[j]
(3)、将分组跳跃式冒泡排序推广到每次跳跃的步长为m的情形,例如对数组a=[6,3,5,4,1,2,8,7]进行分组跳跃式升序冒泡排序,当m=3时,排序后的数组a=[4,1 ,26,3,5,6,7]。相关代码如下,请在划线处填入合适的代码。
import random
m=int(input(“请输入步长m:”))
n=8
a=[random.randint(1,9) for i in range(n)]
print(“排序前”,a)
for i in range()
for j in range()
if a[j]<a[j-m]:
a[j],a[j-m]=a[j-m],a[j]
-
5、有n (n>=3)级台阶,从底端向上爬到顶端,每次只能爬2级或者3级台阶,求从底端爬到顶端的方案数。(1)、当n=5时,方案数为(2)、用迭代法计算爬n级台阶的方案数,python程序如下:
n=int(input())
f0,f1,f2=1,0,1
for i in range(3,n+1):
▲
f0,f1,f2= f1,f2,f3
print("爬n级台阶的方案数为",f3)
则划线处的代码为。该段代码使用了 (填:递归或迭代)算法。
-
6、有如下Python 程序:
import random
s= input()
k = random.randint( l,len(s)-1)
i=0
while k> 0 and i < len(s)-1:
if s[i]>s[i+1]:
k-= 1
s= s[:i]+s[i+1:]
if i> 0:
i-= 1
else:
i+= 1
if k> 0:
s = s[:len(s)-k]
若输入的s值为“8561324”,则执行该程序,输出s的值不可能为( )
A、51324 B、124 C、132 D、1324 -
7、有如下程序段,则该程序段的时间复杂度为( )
a = [0 for i in range(n+1)] for j in range(n+1)]
a[0][0]=1
for i in range(1,n+1):
a[i][0]=1
for j in range(1,i+1)
a[i][i] = a[i-1][j-1]+a[i-1][j]
A、O(log2N) B、O(N) C、O(Nlog2N) D、O(N2) -
8、若某算法的总执行次数T(N)=T(N/2)+1 (N为大于2的正整数),另T(1)=1。则该算法的时间复杂度为( )A、O(N) B、O(log2N) C、O(Nlog2N) D、O(N2)
-
9、有如下程序段:
def cal(n):
if n <= 1:
return 1
if n % 2 == 0:
return 2*cal(n-1)
执行语句k=cal(5),则k的值为( )
A、6 B、7 C、10 D、11 -
10、下列有关迭代算法和递归算法的描述,不正确的是( )A、在使用递归算法时,必须有一个明确的递归结束条件,称为递归出口 B、一般来说,迭代算法效率较低,而递归算法效率较高 C、递归中一定有迭代,但迭代中不一定有递归 D、通常情况下,迭代算法和递归算法可以相互转换
-
11、数组a已有9个数据,分别存储于 a[0]~a[8],需在第j个位置(1≤j≤9)插入数据k。利用Python 语言编写代码,模拟数据插入过程,可选代码如下:
①a[i]=k ②a[i-1]=k ③a[i+1]=a[i] ④a[i]=a[i-1]
⑤for i in range(j,9) ⑥for i in range(8,j-2,-1)

划线处所需代码依次为( )
A、⑥③① B、⑤③② C、⑥④① D、⑤③① -
12、有如下Python程序段:
a=[27,5,25,36,78]
f=[False]*5
i=0
while i<4 and not f[i]:
for j in range(4, i, -1):
if a[j]<a[j-1]:
a[j], a[j-1]=a[j-1], a[j]
f[i]=True
i+=1
执行该程序段后,数组f中值为True的元素个数是( )
A、1 B、2 C、3 D、4 -
13、定义如下函数:
def f(k):
if k<=3:
print(k)
return
for i in range(1,4):
f(k-i)
return
执行语句f(6),则f(3)被调用的次数为( )
A、1次 B、2次 C、3次 D、4次 -
14、下列关于数据与大数据的说法,不正确的是 ( )A、大数据中各种结构化、半结构化和非结构化的数据共存 B、大数据不必追求数据的精确性,不必保证每个数据都准确无误 C、大数据不一定强调事物的因果关系,而是更注重他们的相关性 D、数据量大的一定是大数据,因为大数据的数据体量大
-
15、杭州亚运会吉祥物组合“江南忆”如图所示,这是一副未经压缩的1100*1024像素的BMP图像文件,其存储容量约为1.07MB,则该图像每个像素色彩编码的位数为( )
 A、24 B、16 C、8 D、4
A、24 B、16 C、8 D、4 -
16、下列关于数据、信息与知识的说法,正确的是( )A、数据是对信息加工后获取到的 B、知识表现为一种卓越的判断力 C、传感器的普及加速了数据的传输与处理 D、信息是用来消除随机不确定性的东西
-
17、你认为实现信息安全的办法有哪些?你采取了哪些安全措施?
-
18、信息的表示、传播和存储必须依赖于某种载体,我们日常交流用到的语言、文字等都是信息的载体。( )
-
19、大写字母分段加密。输入 n (n≤50)个大写字母组成的原文字符串,以规模 m 为一段进行加密。加密方法为: (1)找出每段中最长的连续递增子串长度 max; (2)将该段每个字符 后移 max 位进行加密,如果后移后的字母 ASCII 码值超过 90,则从小写字母“a” (ASCII 码 值为 97) 开始表示; (3) 规模不足 m 部分不做处理。
例如: n=10 ,原文字符串为“ABCXYEFDOK”,m=4 时,处理过程如下:
原文字符串
ABCXYEFDOK
分段后
ABCX
YEFD
OK
max 值
4
2
不处理
加密结果
EFGb
aGHF
OK
其中,第 1 段中字母“X”后移 4 位后超过字母“z”的 ASCII 码值,用"b"表示,第 2 段中字母"Y"后移 2 位用“a”表示。
(1)、若原文字符串为“FILVE”,m=3,则加密后的秘文为;(2)、已知加密结果是“RaVJON”,m=4,根据上述加密规则,推得原文是。 -
20、根据下图所示,请将以下操作步骤补充完整。
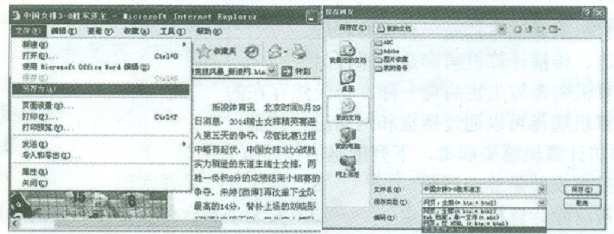
任务:把“中国女排3-0 胜东道主”的网页内容以纯文本文件(.txt)的格式保存到“我的文档”。
操作步骤:
(1)、单击“文件”菜单,选择“”命令;(2)、在“保存网页”对话框中,选定保存位置为“”;(3)、选择“保存类型”为“”,然后单击“保存”按钮。