相关试卷
-
1、录制一段10秒钟立体声、16位量化精度、44.1KHZ的声音,存储这段未经压缩的声音容量是( )A、430.7KB B、861.3KB C、1.68MB D、3.0 MB
-
2、下列方法中,能清除计算机病毒的是( )。A、使用杀毒软件进行全盘杀毒 B、使用消毒液对计算机进行清洗 C、人工找出病毒文件并删除 D、磁盘碎片处理
-
3、在制作多媒体作品时,需要将U盘中的图片“机器人.jpg”移动到“D:\多媒体作品\图片”文件夹中,正确的操作是:( )A、选中“机器人.jpg”→剪切→打开“D:\多媒体作品\图片”文件夹→粘贴 B、选中“机器人.jpg”→复制→打开“D:\多媒体作品\图片”文件夹→粘贴 C、选中“机器人.jpg”→复制→打开“D:\多媒体作品\图片”文件夹→剪切 D、选中“机器人.jpg”→剪切→打开“D:\多媒体作品\图片”文件夹→复制
-
4、小张收集了2017年各季度居民人均收支基本情况的数据,并使用excel软件进行数据处理,如图1所示。请回答下列问题:
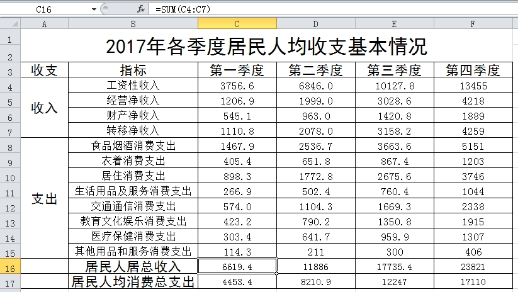 图 1 (1)、“居民人均消费总支出”表示该季度各项支出总和,参照“居民人均总收入”的计算 方法,C17 单元格中的公式应为:。
图 1 (1)、“居民人均消费总支出”表示该季度各项支出总和,参照“居民人均总收入”的计算 方法,C17 单元格中的公式应为:。 图2(2)、根据如图中的数据,制作了 一张反映2017季度居民人均支出基本情况的图表,如图2所示, 创建该图表的数据区域是:。(3)、对区域 B3:F7 按第二季度的数据进 行升序排序,则如图(填:会/不会)发生变化。(4)、将区域A3:F15的数据复制到新工作表并进行筛选操作,筛选设置界面
图2(2)、根据如图中的数据,制作了 一张反映2017季度居民人均支出基本情况的图表,如图2所示, 创建该图表的数据区域是:。(3)、对区域 B3:F7 按第二季度的数据进 行升序排序,则如图(填:会/不会)发生变化。(4)、将区域A3:F15的数据复制到新工作表并进行筛选操作,筛选设置界面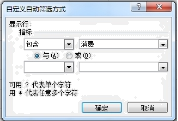
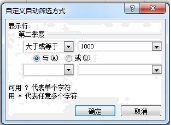
如图所示,则按此设置筛选出的数据共有行。
-
5、有IP地址“00001111111111110000000011110000”,为了使用方便,常用(方法)来表示为(十进制IP地址)
-
6、下图是某主板的一部分,请结合图形完成以下题目。
 (1)、标号①所指部件是用来安装什么设备的?(2)、标号①所指部件安装的设备有哪些性能指标?(3)、在标号①所指部件上安装设备的操作步骤是怎样的?
(1)、标号①所指部件是用来安装什么设备的?(2)、标号①所指部件安装的设备有哪些性能指标?(3)、在标号①所指部件上安装设备的操作步骤是怎样的? -
7、下列关于信息的编码,描述正确的是( )A、3位二进制能表示的最大十进制数是8 B、字符“9”的ASCⅡ码为57,则“10”的ASCⅡ码为58 C、Wave格式音频文件的大小与采样频率、量化位数成正比 D、16色位图图像,每个像素用二进制表示需要16位
-
8、下列关于信息安全的说法正确的是( )A、个人信息泄露的渠道只可能是网上交流时被恶意窃取 B、依靠生物特征识别的认证技术,不需要任何附加设施,成本低、速度快 C、可以通过加密措施来确保信息的完整性,采用数字签名保护信息的不可否认性 D、访问控制要解决的问题是用户对数据操作的权限,是在保障授权用户能获取所需资源的同时拒绝非授权用户的安全机制
-
9、计算机重启后,( )中的数据不会丢失。A、云盘 B、内存 C、U盘 D、硬盘
-
10、下列关于信息的说法中,不正确的是( )A、信息是指数据、信息、消息 B、信息具有时效性和真伪性 C、物质、能源和信息是构成当今人类社会的三大要素 D、人们一时一刻也离不开信息,信息无处不在
-
11、下列有关信息安全的说法正确的是( )A、身份认证解决的是用户对各类数据操作的权限问题 B、访问控制解决的是用户能否正确进入系统的权限问题 C、防火墙般是由硬件和软件组成的复杂系统,也可以仅软件系统 D、用户名+口令的认证技术必须添加能发送动态口令的专用设备
-
12、关于计算机硬件和软件的说法, 不正确的是( )A、操作系统是最重要的系统软件 B、计算机最核心的部件是中央处理器即 CPU,包含运算器和控制器 C、爱奇艺、Photoshop、QQ、Word2010 等软件属于应用软件 D、关闭电源后,随机存取存储器(RAM)中的信息不会丢失
-
13、下列文件中,不能与视频文件“醉美贵州.mpg”合成在一起的是( )。A、配乐.mp3 B、风景素材.avi C、黄果树.bmp D、贵州风景.exe
-
14、阅读下列材料,完成下面小题。
某水果连锁店“智能收银系统”中,AI收银秤具备自动识别水果品种、称重、应付金额计算、扫码支付等功能,同时还具备和服务器数据库进行数据交换的功能。该系统主要设备的部分参数与功能如下表所示:
服务器
AI收银秤
显示器:1280×1024
CPU:八核2.30GHz
硬盘:4TB
操作系统:Linux
显示器:1920×1080 AI摄像头:自动识别水果品种
CPU:四核1.80GHz 扫码摄像头:支持多种付款码扫码
硬盘:64GB 秤体:内置传感器支持精确称重
操作系统:Windows 打印机:打印购物小票
为提升该信息系统数据的安全性,下列措施中不合理的是( )
A、为系统不同的授权用户设置相应的权限 B、非营业时间关闭服务器防火墙 C、升级服务器端杀毒软件 D、定期备份服务器中数据 -
15、利用Windows的任务栏,可以( )A、切换当前应用程序 B、放置常用程序的快捷方式图标 C、放置用户打开的程序或文件 D、改变桌面的排列方式
-
16、下列行为安全隐患最小的是( )A、及时打开陌生人发来的中奖网址链接 B、使用公共场所的免费WiFi ,进行网购和转账 C、从银行官网下载安装银行客户端进行网上支付 D、随意下载和安装智能手机客户端APP软件
-
17、现有一个大小为n*n的平面矩阵(从上到下从左到右编号为1~n*n),矩阵中有诸多障碍物。有两个机器人分别为1号和2号,其中1号位于左上角且面朝右侧,2号位于右下角且面朝左侧。现在机器人需要按照规则进行K轮运动,规则如下:
①1号和2号机器人需要交替运动,即第一轮由1号进行运动,第二轮则由2号进行运动,第三轮由1号进行运动……以此类推直至第K轮。
②每轮运动时,机器人将先判断前方是否可以前进,若无法前进,则不断顺时针旋转90°至可以前进为止,随后前进直至停止,由另一个机器人开始下一轮运动。
③机器人在前进过程中遇到边界、障碍物或者另一个机器人时都将停止。
如图a所示,机器人1号和2号分别位于左上角和右下角,且分别朝向右侧和左侧,黑块表示障碍物,当进行了4轮运动后,状态如图b所示。
编写程序,启动后随机生成矩阵并在List1中输出,其中"#"表示障碍物,"_"表示可以行走的空格子,机器人用数字1和2表示。在文本框Text1中输入轮数K,点击按钮Command1,在列表框List1中输出K轮后的矩阵。程序界面如图c所示。
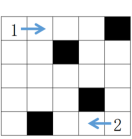
图a
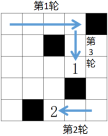
图b
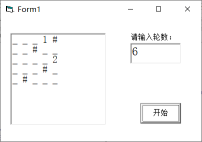
图c
(1)、若在图a的基础上进行6轮运动后,1号机器人所在的位置是(填行列或格子编号均可)。(2)、实现上述功能的部分VB程序如下,请在划线处填入合适的代码。Const n = 10
Dim a(100) As String, steps(3) As Integer, pos(2) As Integer
Dim towards(2) As Integer, cur As Integer, nex As Integer, K As Integer
Private Sub Form_Load()
'生成矩阵存储在数组a中并输出,代码略
End Sub
Private Sub Command1_Click()
steps(0) = -n: steps(1) = 1: steps(2) = n: steps(3) = -1
pos(1) = 1: towards(1) = 1: pos(2) = n * n: towards(2) = 3
i = 1 : K = Val(Text1.Text)
Do While i <= K
cur = (i - 1) Mod 2 + 1
nex = GetNext(pos(cur), towards(cur))
Do While Check(nex)
pos(cur) = nex
nex = GetNext(pos(cur), towards(cur))
Loop
nex = GetNext(pos(cur), towards(cur))
Do While Not Check(nex)
towards(cur) =
nex = GetNext(pos(cur), towards(cur))
Loop
i = i + 1
Loop
'输出矩阵,代码略
End Sub
Function Check(x As Integer) As Boolean
Check = x <> 0 And a(x) <> "#" And
End Function
Function GetNext(x, t) As Integer
GetNext = x + steps(t)
If x >= 1 And x <= n And t = 0 Then GetNext = 0
If x > (n - 1) * n And x <= n * n And t = 2 Then GetNext = 0
If Then GetNext = 0
If x Mod n = 0 And t = 1 Then GetNext = 0
End Function
-
18、星期天,小龙来到动物园游玩,园内共有N个景点(可在10个以上),每个景点都有一个标号,标号为1至N。现在只知道每个景点有一条路连接下一个景点。小龙想知道,根据这些道路信息,从其中一个景点出发,最后再回到出发景点,最多能游玩多少个景点。
例如,共有N=5个景点,每个景点连接的下一个景点分别是2,4,5,5,2。
景点号
1
2
3
4
5
下一景点号
2
4
5
5
2
则他可以从2号景点出发,最多可以游玩2号、4号、5号三个景点。
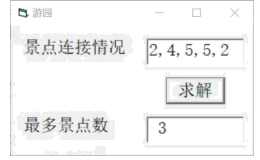
程序代码如下:
Private Sub Command1_Click()Dim a(1 To 100) As Integer, d(1 To 100) As Integer
Dim jd As String, m As String, c As Integer, i As Integer
Dim s As Integer, p As Integer, k As Integer, ans As Integer
jd = Text1.Text + ","
s = 0: c = 0
For i = 1 To Len(jd)
m = Mid(jd, i, 1)
If m <> "," Then
①
Else
c = c + 1: a(c) = s: s = 0
End If
Next i
ans = 0: k = 0
For i = 1 To c
For k = 1 To c
d(k) = 0
Next k
If d(i) = 0 Then
p = i
Do While p <= c
If d(p) = 0 Then
k = k + 1: d(p) = k
Else
If y > ans Then ans = y
k = 0
Exit Do
End If
Loop
End If
Next i
Text2.Text = Str(ans)
End Sub
(1)、要使程序运行时,Form1的BackColor属性值为黑色,以下代码正确的是(单选,填字母)。A .Private Sub Form_Load()Form1. BackColor = RGB(255, 255,255)
End Sub
B .Private Sub Form_Load()Form1.BackColor = RGB(0, 0, 0)
End Sub
C .Private Sub Form1_Load()orm1.BackColor = RGB(255,255,255)
End Sub
D .Private Sub Form1_Load()Form1.BackColor = RGB(0, 0, 0)
End Sub
(2)、若有7个景点,且每个景点的连接情况为:6,3,7,2,7,5,4,那么小龙最多可以游玩的景点数是。(3)、请把划线处的代码补充完整:①
②
(4)、程序加框处代码有错,请改正:。 -
19、VB表达式int(-3.1)的值是。
-
20、写出算法执行结果
A=31415
S=0
Do while A>0
s = s + A mod 10
A= A\10
Loop
PRINT S