浙江省钱塘联盟2023-2024学年高二上学期信息技术期中联考试卷
试卷更新日期:2023-11-29 类型:期中考试
一、选择题(本大题共13小题,每小题2分,共26分。每小题列出的四个选项中只有一个是符合题目要求的,不选、错选、多选均不得分。)
-
1. 下列关于数据、信息和知识的描述,正确的是 ( )A、数据就是指各种数字 B、信息是数据的载体,数据是信息的内涵 C、获取了信息就拥有了知识 D、知识是人们在社会实践中所获得的认知和经验的总和2. 某声音模拟信号的采样及量化函数模型如下图所示,下列说法不正确的是( )
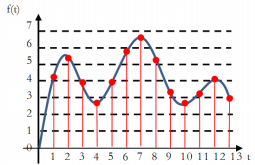 A、图中横坐标划分得越细表示采样频率越高,保真度越高 B、图中整个幅度分为 0~7 级,其量化位数至少为 8 位 C、声音数字化过程是将连续的模拟信号转换成离散的数字信号 D、声音经过数字化后,以二进制编码的形式被计算机存储、处理3. 下列关于数据管理与安全的说法不正确的是( )A、数据的完整性可采用 MD5 校验方法来验证 B、借助云计算与大数据等技术,能提高数据管理水平 C、数据安全就是保障数据不被损坏 D、为防止系统停止工作时造成数据丢失,可通过容灾系统来解决4. 下列关于大数据的说法正确的是 ( )A、大数据注重事物的因果关系而不重视相关性 B、大数据处理技术是自古就有的 C、大数据的特征:体量大,速度快,数据类型多,价值密度低 D、大数据技术通过抽样数据的方法处理数据5. 某算法的部分流程图如题图所示。执行这部分流程,若输入 s 的值为“qiantang”,则输出的 c、i 值分别为 ( )
A、图中横坐标划分得越细表示采样频率越高,保真度越高 B、图中整个幅度分为 0~7 级,其量化位数至少为 8 位 C、声音数字化过程是将连续的模拟信号转换成离散的数字信号 D、声音经过数字化后,以二进制编码的形式被计算机存储、处理3. 下列关于数据管理与安全的说法不正确的是( )A、数据的完整性可采用 MD5 校验方法来验证 B、借助云计算与大数据等技术,能提高数据管理水平 C、数据安全就是保障数据不被损坏 D、为防止系统停止工作时造成数据丢失,可通过容灾系统来解决4. 下列关于大数据的说法正确的是 ( )A、大数据注重事物的因果关系而不重视相关性 B、大数据处理技术是自古就有的 C、大数据的特征:体量大,速度快,数据类型多,价值密度低 D、大数据技术通过抽样数据的方法处理数据5. 某算法的部分流程图如题图所示。执行这部分流程,若输入 s 的值为“qiantang”,则输出的 c、i 值分别为 ( )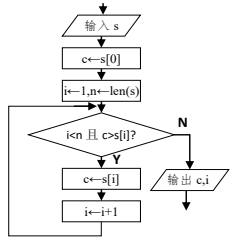 A、"a",2 B、"a",3 C、"a",5 D、"t",46. 若 x 是整型变量,下列选项中,与表达式 not(x>=0 and x<8)含义相同的是( )A、x<0 and x>=8 B、x<0 or x>=8 C、x>=0 or x<8 D、not x>=0 and not x<87. 一个班的学生排成一列,从第一位同学开始按 1-6 循环报数,能正确表示第 n 位同学所报数字的Python 表达式是 ( )A、n%6 B、n C、(n-1)%6+1 D、(n+1)%6-18. a="345",若要构造其回文数 b 为"34543",以下语句无法实现的是 ( )A、b=a+a[-2:-4:-1] B、b=int(a)*100+int(a[1::-1]) C、b=a+a[1]+a[0] D、b=(a[0]+a[1]+a[2])*29. 已知 a="012345",b=["012",3,4,5],c= {0:1,2:4,3:5},下列语句执行完毕后,s 的值为 5 的是 ( )A、s=0
A、"a",2 B、"a",3 C、"a",5 D、"t",46. 若 x 是整型变量,下列选项中,与表达式 not(x>=0 and x<8)含义相同的是( )A、x<0 and x>=8 B、x<0 or x>=8 C、x>=0 or x<8 D、not x>=0 and not x<87. 一个班的学生排成一列,从第一位同学开始按 1-6 循环报数,能正确表示第 n 位同学所报数字的Python 表达式是 ( )A、n%6 B、n C、(n-1)%6+1 D、(n+1)%6-18. a="345",若要构造其回文数 b 为"34543",以下语句无法实现的是 ( )A、b=a+a[-2:-4:-1] B、b=int(a)*100+int(a[1::-1]) C、b=a+a[1]+a[0] D、b=(a[0]+a[1]+a[2])*29. 已知 a="012345",b=["012",3,4,5],c= {0:1,2:4,3:5},下列语句执行完毕后,s 的值为 5 的是 ( )A、s=0for i in a[5]:
s=s+1
B、s=0for i in range(b[2]):
s=s+1
C、s=0while s<=c[2]:
s=s+1
D、s=0while s>c[3]:
s=s+1
10. 某 Python 程序段代码如下, 与该程序段功能等价的是( )if x>90:
y=x*0.5 else:
y=x*0.9
A、if x>90:y=x*0.5 y=x*0.9
B、if x<90:y=x*0.9 else:
y=x*0.5
C、y=x*0.9 if x>90:y=x*0.5
D、if x>90:y=x*0.5 if x<90:
y=x*0.9
11. 下列语句用于计算 s=1+2+5+8+11+…+26 的结果并输出,则 range 函数的各个参数为( )s=1
for i in range(_):
s=s+i print(s)
A、1,26,3 B、1,27,3 C、2,26,3 D、2,27,312. 某 Python 程序如下:s="Dijob 2023" s1=""
for i in range(0,len(s)):
c=s[i]
if "a"<=c<="z" or "A"<=c<="Z":
s1=s1+chr(ord(c)-1)
else:
s1=c+s1 print(s1)
程序运行后,输出的结果是 ( )
A、China 2023 B、3202 China C、2023 China D、China 320213. 有如下 Python 程序段:import random s="12345678"
g=""
for i in range(3):
n=len(s)
pos=random.randint(1,n-1)
g+=s[pos]
s=s[0:pos]+s[pos+1:n] print(g)
在该程序段执行时,变量 g 的值可能为 ( )
A、"542" B、"138" C、"336" D、"15"二、 非选择题(本大题共 3 小题,7+7+10,共 24 分)
-
14. 编写一个“计算多边形周长”的程序。功能如下:输入多边形的边的数量和顶点的坐标值,程序计算各条边的长度,并输出该多边形的周长。例如,输入多边形的边的数量为 4,各顶点的坐标分别为(0,0)、(2,4)、(3,5)、(6,6),运行结果如图所示。
请输入多边形的边的数量:4
请输入多边形顶点的横坐标:0
请输入多边形顶点的纵坐标:0
请输入多边形顶点的横坐标:2
请输入多边形顶点的纵坐标:4
请输入多边形顶点的横坐标:3
请输入多边形顶点的纵坐标:5
请输入多边形顶点的横坐标:6
请输入多边形顶点的纵坐标:6
{1: [0, 0], 2: [2, 4], 3: [3, 5], 4: [6, 6]}
多边形的周长为: 17.533908551779625
d={} s=0
n=int(input("请输入多边形的边的数量:"))
for i in range(1, ① ):x=int(input("请输入多边形顶点的横坐标:"))
y=int(input("请输入多边形顶点的纵坐标:"))
d[i]=[x,y] print(d)
j=n
while j>1:
x1=d[j][0]-d[j-1][0]
y1= ①
s=s+(x1**2+y1**2)**0.5
②
s=s+((d[n][0]-d[1][0])**2+(d[n][1]-d[1][1])**2)**0.5
print("多边形的周长为:",s)
(1)、该算法是否可以运用到计算圆周长的场景中(选填:是/否)。(2)、请在划线处填入合适的代码。① ② ③
15. 筛法求素数。埃拉托斯特尼筛法,简称埃氏筛或爱氏筛,是一种由希腊数学家埃拉托斯特尼所提出的一种简单鉴定素数的算法。要得到自然数 n 以内的全部素数,必须把不大于根号 n 的所有素数的倍数剔除,剩下的就是素数。算法思想:先用 2 去筛,即把 2 留下,把 2 的倍数剔除掉;再用下一个质数,也就是 3 筛,把3 留下,把 3 的倍数剔除掉;接下去用下一个质数 5 筛,把 5 留下,把 5 的倍数剔除掉;不断重复下去……
现在使用埃氏筛法求 1~n 之间的素数个数,代码如下:
n=int(input())
a=[1]*(n+1)
a[0],a[1]=0,0 #标记小于 2 的数, 0 表示非素数,1 表示素数
① i=2
while i<=n:
if ② :
for j in range(2*i,n+1,i):
a[j]=0
i+=1
for i in range(n+1):
③ print(num)
(1)、若输入的值为 20,则输出为。(2)、请在划线处填入合适的代码。① ② ③
16. 叶圣陶杯作文大赛开始了,语文老师收集了参赛同学的作文,作品的文件名按“学号&姓名.docx” 格式提交。学号为 8 位,第 10 位开始为姓名,如“20210902&王源.docx”。老师编写了一段程序以便快速找出哪些同学未提交以便于进行通知处理。在处理时发现,可能会存在“ 20210901+王俊凯.docx”“20210901-王俊凯.docx”两种不当的格式。(1)、读取文件名并返回,请在划线处填入合适的代码import osdef readname(): #读取某个文件夹内所有文件的文件名
filepath="pics//"
#读取到的文件名以字符串的形式,作为元素存储在列表 allname 中
allname=os.listdir(filepath)
#os.listdir()用于返回指定的文件夹包含的文件或文件夹的名字的列表
return
(2)、修改文件中的“+”和“-”,请在划线处填入合适的代码def checkname(name):
s=""
for i in name:
if i=="+" or i=="-":
s+="&"
else:
s=s[:-5] #去掉后四位,即去掉后缀名".docx"
return s
(3)、主程序,请在划线处填入合适的代码name=readname()
student=["王俊凯","王源","张明","赵祖一","吴天","顾玲玲","方奔奔","张强"] yes=[];no=[];s=0;result={}
for item in name:
item=checkname(item)
yes.append(stu) #将学生的姓名加入列表
s=s+1
for m in student:
if:
no.append(m)
(4)、输出结果result[" 应 提 交 人 数 :"]=len(student)
result[" 已 提 交 人 数 :"]= ▲
result["已提交的同学:"]=yes
result["还未提交的同学:"]=no
print(result)
划线处可以填入的代码是 (多选,填字母)
A、len(yes) B、s C、len(no) D、len(name)