浙江省杭州市周边重点中学2022-2023学年高二下学期信息技术4月期中试卷
试卷更新日期:2023-05-19 类型:期中考试
一、选择题(本大题共13小题,每小题2分,共26分。每小题列出的四个备选项中只有一个符合题目要求,不选,错选、多选均不得分。)
-
1. 阅读下列材料,回答问题。
ChatGPT是由OpenAI在2022年11月30日发布的全新聊天机器人模型,一经推出,迅速在社交媒体上走红,短短5天,注册用户数就超过100万。ChatGPT是人工智能技术驱动的自然语言处理工具,使用了Transformer神经网络架构,会通过连接大量的语料库来训练模型,使得ChatGPT具备上知天文下知地理,还能根据聊天的上下文进行互动,真正像人类一样聊天交流,甚至能完成撰写文案、代码、写论文等任务。
(1)、下列有关数据和信息说法不正确的是:( )A、材料中的 100 是数据,数据的表现形式可以是文字、图形、图像、音频等 B、数据不是信息, 信息是数据经过解释所产生的意义 C、对所有用户而言,使用 ChatGPT 获取信息的价值是相同的 D、ChatGPT 迅速在社交媒体上走红, 说明信息具有共享性(2)、下列有关人工智能的说法正确的是:( )A、多层神经网络是一种典型的深度学习模型, 不依赖训练数据 B、ChatGPT 上知天文下知地理,说明人工智能可以模拟人脑的全部智能 C、人工智能在不同的岗位取代人类, 但从长期来看科技带来的就业远大于失业 D、人工智能技术推动人类社会进步的同时,不可能威胁人类安全2. 下列关于数制和编码的说法正确的是:( )A、将末位为 0 的十六进制数转换为二进制数后,二进制数的末位不一定是 0 B、将模拟信号转换成数字信号存入计算机,不会引起失真 C、汉字在计算机内部采用十六进制编码, 一个汉字占用 2 个字节 D、二维码比一维条形码存储容量更大,功能更强3. 下列有关大数据的说法不正确的是:( )A、大数据具有数据体量大、速度快、数据类型多、价值密度低的特征 B、大数据由于量太大, 因此只做抽样样本分析 C、处理大数据时, 一般采用“分治”思想 D、网络的实时个性化推荐适合采用流计算处理数据4. 以下行为符合个人信息安全要求的是:( )A、在电脑上安装并及时更新病毒检测软件 B、在手机上打开中奖短信链接 C、积极配合陌生电话的问卷调查 D、购买 QQ 群里低价出售的游戏稀有装备5. 下列有关数据结构的说法不正确的是:( )A、频繁进行数据插入和删除操作,链表效率要比数组高 B、单击浏览器“后退”按钮可回到刚才浏览过的网页, 说明网页数据是采用栈进行组织的 C、队列是一种先进先出的线性表,插入一端为队首,删除一端为队尾 D、使用数组在进行数据插入和删除操作时,不一定会引起数据移动6. 某算法的部分流程图如图所示,执行这部分流程,若输入g的值依次为 18,28,36,60, 则输出值 s,i 依次为:( )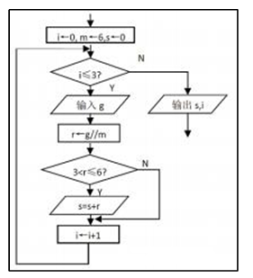 A、20,3 B、10,4 C、10,3 D、13,47. 下列 python 表达式的值为False的是:( )A、2**4>=4**2 B、3 in ["3","6"] C、len(str(1)+"3")<13 D、3*4//5%2+4==48. 左右对称的字符串称回文串。若要判断字符串s是否为回文串,可以先找到s的中间位置mid=len(s)//2;再采用切片操作取出s的左半部分left=s[0:mid];然后取出s的右半部分并反转 , 存储在变量right中;若left与right相等,则为回文串。则下列表达式能正确表达变量right值的是:( )A、s[mid::][::-1] B、s[mid+1::] [::-1] C、s[len(s)-1:mid:-1] D、s[-1:-mid-1:-1]9. 有如下 Python 程序段:
A、20,3 B、10,4 C、10,3 D、13,47. 下列 python 表达式的值为False的是:( )A、2**4>=4**2 B、3 in ["3","6"] C、len(str(1)+"3")<13 D、3*4//5%2+4==48. 左右对称的字符串称回文串。若要判断字符串s是否为回文串,可以先找到s的中间位置mid=len(s)//2;再采用切片操作取出s的左半部分left=s[0:mid];然后取出s的右半部分并反转 , 存储在变量right中;若left与right相等,则为回文串。则下列表达式能正确表达变量right值的是:( )A、s[mid::][::-1] B、s[mid+1::] [::-1] C、s[len(s)-1:mid:-1] D、s[-1:-mid-1:-1]9. 有如下 Python 程序段:a=[1,5,9,2,6,8,3,4,7] n=0 ;flag=True
for i in range(len(a)-1):
if a[i]<a[i+1] and flag==True:
n+=1;flag=False
elif a[i]>a[i+1] and flag==False:
n-=1;flag=True
print(n)
执行上述程序段后, 输出的值为:( )
A、2 B、0 C、-1 D、110. 有1个队列,队首到队尾的元素依次为1,2,3,4,5。约定:T操作是指队列中1个元素出队后再入队,Q操作是指队列中1个元素出队。则经过TTQTTQTTQ系列操作后,队列中队首到队尾的元素依次为:( )A、4,5 B、5,4 C、2,4 D、4,211. 有如下 Python 程序段:import random
p="abcde*";st=[] ;s="";i=0
while i<=5:
m=random.randint(0,1)
if m==0:
st.append(p[i])
i+=1
elif len(st)>0:
s+=st.pop()
print(s)
执行上述程序段后,输出结果可能的是:( )
A、a* B、cdabe C、abcde* D、cdba12. 有两个降序序列的链表a,b。现将链表b中的数据合并到链表a,形成一个新的降序序列存于链表a,实现数据合并的代码段如下:a = [[98,1],[96,2],[95,3],[93,4],[90,-1]];b = [[99,1],[97,2],[94,3],[93,4],[92,-1]] head_a = head_b = 0
pre = p = head_a;q = head_b
while q!=-1:
if p!=-1 and (1) :
pre=p
p=a[p][1]
else:
a.append( (2) )
if p==head_a:
pre=head_a=len(a)-1
else:
a[pre][1]= (3)
pre=len(a)-1
q=b[q][1]
上述程序段中可选填的语句为:
①a[p][0]>= b[q][0] ② a[p][0]<= b[q][0] ③q
④len(a)-1 ⑤[b[p][0],q] ⑥[b[q][0],p]
则划线处填写的语句依次为:( )
A、①⑥④ B、①⑤④ C、①⑥③ D、②⑥③二、非选择题(本大题共3小题,7+8+9,共24分)
-
13. 信息时代要提升个人信息安全意识,确保个人信息安全,需经常修改登录密码,小明设计一种字符加密方法,用原密码加密生成新密码。他设计的加密规则如下:
㈠将原密码中的小写字母转换成大写字母;
㈡将原密码中的大写字母转换成小写字母;再利用移位秘钥中对应的数字循环右移,移位秘钥不够时可以循环使用。如移位秘钥为“312”,待加密字母“abcde”,则应将字母a,b,c,d,e分别循环右移3位、1位、2位、3位、1位;
㈢将原密码中的数字转换为与其对称的数字,例如:0→9,3→6,5→4……9→0;
㈣原密码中其它特殊字符不改变。
程序运行界面如图所示,实现上述功能的程序代码段如下:

def change(zf):
if "A"<=zf<="Z":
s=zf.lower() else: #将字符 zf 中的大写字母转化为小写字母
else:
s=zf.upper() #将字符 zf 中的小写字母转化为大写字母
return ①
pw=input("请输入原密码:")
yw=input("请输入移位秘钥: ") res="";n=0
for ch in pw:
if "a"<=ch<="z":
ch=change(ch)
 "A"<=ch<="Z": ch=change(ch)
"A"<=ch<="Z": ch=change(ch)ch=chr((ord(ch)-97+int(yw[n]))%26+97)
n= ②
elif "0"<=ch<="9":
ch= ③
res=res+ch
print("生成新密码:",res)
(1)、请在划线处填上合适代码。① ② ③
(2)、若将加框处代码 elif 改为 if,则第 14 图中生成的新密码为: 。14. 某中学高一年级完成一次7选3意向调查,数据存储在“xk73.xlsx”中,如图a所示,其中1代表选择科目,0代表弃选科目。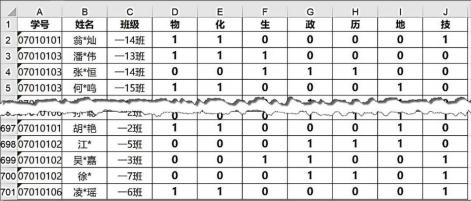 图a(1)、使用 pandas 编程计算本次选课各门课人数占总人数的比例, 请在划线处填入合适的代码。
图a(1)、使用 pandas 编程计算本次选课各门课人数占总人数的比例, 请在划线处填入合适的代码。import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#图表显示中文
df=pd.read_excel (" ")
a=[""]*len(df) #存储每个学生的选课组合
dic={"物":0,"化":0,"生":0,"政":0,"历":0,"地":0,"技":0}
for i in df.index:
for j in df.columns[3:]:
if df.at[i,j]==1:
a[i]+=j
for i in dic.keys():
dic[i]=round(dic[i]/len(df)*100,2)
(2)、按照各科选考人数占比创建如图b所示的图表。 图 b
图 bdf1=pd.DataFrame({"学科":dic.keys(),"人数占 比":dic.values()})
df1= ①
plt.title("各科选考人数占比")
plt.bar ( ② , label="人数占比") plt.legend()
plt.show ()
观察图所示,横线处应填入的代码: ① ② (选填字母)
A.df1.sort_values("人数占比",ascending=True)
B.df1.sort_values("人数占比",ascending=False)
C.df1.学科,df1.人数占比
D.df1.人数占比, df1.学科
(3)、小李同学想查询某种七选三组合的有多少人。以下程序代码可以为小李同学提供查询功能,程序运行示例如图c所示,请在划线处填上合适代码。 图 c
图 ccx=input("请输入需要查询的选课组合: ")
cnt=0
for i in range(len(a)):
if :
cnt=cnt+1
print(f"选择{cx}组合的同学共有: {cnt}人")
15. 某工厂需要加工n批货物,但同一时间只能加工同一批货物。货物的信息包含送达时间、加工时间和是否加急(0表示不加急,1表示加急),每批货物的送达时间各不相同,已送达的货物按照是否加急分别排队,先到达先入队,每次加工都优先处理加急货物队列,选取队首货物出队进行加工(同一时刻出现入队和出队时,先处理入队)。求出所有货物的平均等待时长,其中每批货物等待时长为其开始加工的时间与送达时间的时间差。(1)、由题意可知,图中待加工货物A、B、C、D、E的加工顺序应为A-C-B-E-D。A、C、B、E的等待时长分别为0、0、2、1、那么D等待时长为:;货物编号
送达时间
加工时间
是否加急
A
0
2
0
B
1
3
0
C
2
1
1
D
4
2
0
E
5
2
1
(2)、实现模拟加工过程并计算平均等待时长的部分Python程序段如下,请在划线处填入合适代码。读取n批待加工货物信息存于列表data,data中的数据已经按货物送达时间升序排列。例如存储题中实例的数据:
data=[["A",0,2,0],["B",1,3,0],["C",2,1,1],["D",4,2,0],["E",5,2,1]] '''
n=len(data)
qA=[0]*n;qB=[0]*n
headA=0;tailA=0
headB=0;tailB=0
curtime=0 ;i=0 ;sum=0
while i<n or headA!=tailA or headB!=tailB:
if i<n and data[i][1]<=curtime:
k=data[i][3]
if :
qA[tailA]=i
tailA+=1
else:
qB[tailB]=i
tailB+=1
elif
 :
:if headA!=tailA:
p=qA[headA]
headA+=1
else:
p=qB[headB]
headB+=1
curtime+=data[p][2]
else:
curtime=data[i][1]
print("平均等待时间为:",sum/n)
(3)、加框处代码错误,请改正。