浙江省五校联盟2022-2023学年高二上学期信息技术期末联考卷
试卷更新日期:2023-03-22 类型:期末考试
一、选择题(本大题共12小题,每小题2分,共24分。每小题列出的四个备选项中只有一个是符合题目要求的,不选、多选、错选均不得分)
-
1. 下面一段话,在微信朋友圈被刷屏:“如果‘阳’了的话,丢垃圾的时候最好消杀一下或用“鹅颈式封扎法”进行处理,因为很多垃圾清运人员是老人,他们更弱势”。下列说法不正确的是( )A、“如果‘阳’了的话”这句话中的“阳”是数据 B、“很多垃圾清运人员是老人,他们更弱势”,这是知识的体现 C、如果‘阳’了的话,丢垃圾不进行处理,垃圾清运人员易感染,这体现了信息的载体依附性 D、“鹅颈式封扎法”是人类智慧的体现2. 下列关于信息编码的描述,正确的是( )A、每个中文汉字的输入码是唯一的 B、录音的过程就是通过采样和量化实现数字信号的模拟化过程 C、根据GB2312编码,“世界足球杯”共占10bit D、已知大写字母I的ASCII码是49H,则小写字母j的ASCII 码是106D3. 关于数据管理与安全,下列说法正确的是( )A、计算机数据的管理已经先后经历了文件管理、人工管理、数据库管理 B、安装正版的杀毒软件并及时更新就一定能保证计算机的数据安全 C、数据校验提高了数据的保密性 D、常有的数据校验方法有MD5、CRC、SHA-1等4. 阅读材料,完成问题
北京体育大学研究团队建立了无反光点人体运动自动捕捉人工智能系统,曾助力中国选手巩立姣和刘诗颖在东京奥运会女子投掷项目比赛中出色发挥,分获铅球和标枪金牌。目前该系统已应用在国家速度滑冰和越野滑雪项目的训练中,获得超过8000人次的赛时动作技术数据,使机器深度学习越发“得心应手”,对于滑冰与滑雪运动员的动作捕捉与技术分析,既能精准到具体细节,又能快速反馈分析结果。
(1)、根据以上描述,下列说法不正确的是( )A、随着获取的动作数据逐渐增加,该技术对于数据的反馈会更有效 B、材料中“获得超过8000人次的赛时动作技术数据,使机器深度学习越发‘得心应手’”说明 大数据分析的是全体数据,而不是抽样数据 C、该技术捕捉到的每一个数据都来自于真实数据,体现了大数据价值密度高的特点 D、能根据动作自动捕捉进行分析,并快速反馈分析结果,体现了大数据速度快的特点(2)、根据以上材料中的描述,人工智能技术助力运动员主要基于以下哪种方法( )A、符号主义 B、联结主义 C、行为主义 D、建构主义5. 录制一段采样频率为44.1kHz,量化位数为16位的双声道立体环绕的Wave音频格式数据16秒,需要的磁盘空间大约为( )A、3MB B、5MB C、30MB D、20MB6. 某算法的部分流程图如图所示。执行这部分流程,若输入m的值为“append”,则输出c,a的值分别为( ) A、p 2 B、e 3 C、p 3 D、e 47. 下列表达式中,值为True 的 是 ( )A、not abs(-12.7)>12 B、3**2<=2**3 C、round(3.1415,3)==3.141 and“2”in“3+27” D、3!=1+2 or 5>=58. 有如下Python 程序段:
A、p 2 B、e 3 C、p 3 D、e 47. 下列表达式中,值为True 的 是 ( )A、not abs(-12.7)>12 B、3**2<=2**3 C、round(3.1415,3)==3.141 and“2”in“3+27” D、3!=1+2 or 5>=58. 有如下Python 程序段:s=input()
y=""
for i in range(len(s)):
c=s[i]
if c>="A" and c<="Z":
c=chr(ord(c)+3)
y=c+y
print(y)
运行上述程序,若输入的s内容为“A1b2C3”,则显示的是:( )
A、A1b2C3 B、D1b2F3 C、3F2b1D D、3C2b1A9. 有如下Python程序段:def s(b):
n=b[0]
for i in b:
if i>n:
n=i
return n
a=[20,10,70,30]
print(s(a))
该程序段执行后,输出结果为( )
A、10 B、20 C、30 D、7010. 有如下Python 程序段:n=int(input( ))
s=0;i=1
while i*i<=n:
if i==n//i:
s+=1
elif n%i==0:
s+=2
i+=1
print(s)
若输入”16”,该程序段执行后,输出的结果是( )
A、3 B、4 C、5 D、611. 有如下Python程序段:from random import randint
s=[60,40,70,20,10,50]
m=randint(1,3)*2
for iin range(6, m):
for jin range(5,i,-1):
if s[j- 1]>s[j]:
t=s[j]
s[j]=s[j-1]
s[j-1]=t
print(s)
该程序段执行后,输出的结果不可能是( )
A、[60,40,70,20,10,50] B、[10,60,40,70,20,50] C、[10,20,60,40,70, 50] D、[10,20,40,50,60,70]二、非选择题(本大题共4小题,6+7+7+6,共26分)
-
12. 分解质因数是指一个整数可以写成几个质数相乘的形式。现有如下Python程序段实现对一个整数(可以为负整数)分解质因数,如输入正整数15,输出结果为:15=3*5,输入负整数-4,输出结果为:-4=-1*2*2。(1)、请在划线处填入合适的代码。
x=int(input("输入一个整数:")
s=str(x)+"="
if x<0:
x=-x
s+="-1*"
i=2
while x>1:
while x%i==0:
s+=str(i)+"*"
i+=1
print( )
(2)、当输入整数-40时,输出的结果为13. 某市普通高中选课数据文件“xk73.xlsx”如图-1所示,学生从物理、化学、生物等七门课中选三门作为高考选考科目,“1”表示已选择的选考科目。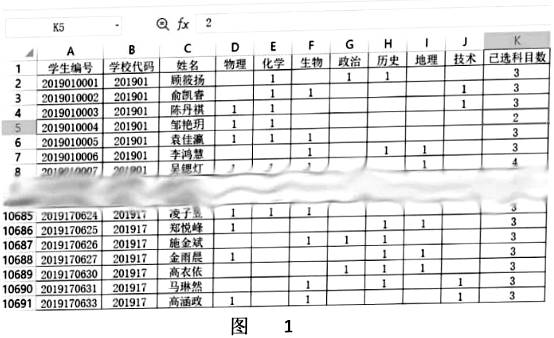 (1)、按选课要求每位学生都应从物理、化学、生物等七门课中选三门,即“已选科目数”列的值应为“3”,但是从上图中发现“已选科目数”列中有不是“3”的数字,需要该数据进行整理,该数据问题属于 (单选: A . 数据缺失; B . 数据异常; C . 数据重复)(2)、现用Python语言编程统计每所学校各科目选考的总人数,全市各科选考总人数,并按技术选考人数创建图表,如图2,图3所示。代码如下:
(1)、按选课要求每位学生都应从物理、化学、生物等七门课中选三门,即“已选科目数”列的值应为“3”,但是从上图中发现“已选科目数”列中有不是“3”的数字,需要该数据进行整理,该数据问题属于 (单选: A . 数据缺失; B . 数据异常; C . 数据重复)(2)、现用Python语言编程统计每所学校各科目选考的总人数,全市各科选考总人数,并按技术选考人数创建图表,如图2,图3所示。代码如下:

import pandas as pd
import itertools #包含了 一 系列迭代器相关的函数和类
import matplotlib.pyplot as plt
import codecs #处理中文 utf-8编 码
from matplotlib.font manager import FontProperties
#读数据到 Pandas 的 DataFrame 结构中
df=pd.read excel(" ")
km=['物理','化学';'生物,'政治';历史,'地理','技术']
zrs=len(df.index) #总人数
#按学校分组计数
sc=df.groupby('学校',asindex=False).count()
result = #删除“姓名”列
result = result.rename(columns={'学生编号:总人数'})#修改“学生编号”为“总人数”
del result['已选科目数']
# 创 建 如图3 所 示 图 表
font=FontProperties(fname=r"c:\windows\fonts\simkai.ttf",size=12)
plt.rcParams["font.sans-serif"]=["KaiTi"]
plt.title("全市技术选考总人数对比情况")
plt.xlabel("学校")
plt.ylabel("技术")
plt.legend( )
plt.show( )
#保存结果
result.toexcel("学校人数统计.xlsx")
根据题意,请在划线处填入合适的语句或表达式
14. 寻找字符串中连续数字(全部分解为1位数)之和为s的全部字串,如字符串”20210521”中和为6的字串为”105”。实现该功能的Python程序代码如下,运行界面如图所示。
请在划线处填写正确的代码:
a=input("输入数字字符串:")
i=0;j=0;s=6;sum=0;flag=False
while j<len(a):
sum+=int(c)
whiles:
n=a[i]
i+=1
if sum==s
print("符合条件的字串为:")
flag=True
if not flag:
print("没有符合要求条件的字串")
15. 某高中高二年级一共16个班举行篮球比赛,每个班都与其他班级各进行一场比赛,赢一场比赛增加1点积分,平局或者输掉比赛不扣积分,以最后的积分决定冠军、亚军和季军。如果两个班级胜场数相同,则输场数更低的班级排名更高;如果胜场数和输场数都相同,则排名相同。小文想用python来模拟16个班级的比赛,首先初始化16个班级比赛积分情况,初始化界面(如图1所示),某次运行代码后,16个班级的比赛结果情况如下(如图2所示)

每个班级与其他班级的比赛结果随机生成,0表示平局,-1表示输掉比赛,1表示赢得比赛,第一行数据表示1班对战16个班的比赛结果(每个班和自己的对战结果都用平局表示)
代码如下,请完成代码填空:
import random
import pandas as pd
s=[[0 for i in range(16)]
for jin range(16)] #生成16*16的二维列表(图1所示)
k=[];n=[]
m=[[1,0,0],[2,0,0],[3,0,0],[4,0,0],[5,0,0],[6,0,0],[7,0,0],[8,0,0],[9,0,0],[10,0,0],[11,0,0],[12,0,0],[13,0,0],[ 14,0,0],[15,0,0],[16,0,0]]
#m列表[1,0,0]中第一个元素表示第几班,第二个元素表示胜场数,第三个元素表示输场数以此类推
for i in range(1,16):
for j in range(i):
s[i][j]=random.randint(-1,1)
df=pd.DataFrame(s,index=["1班","2班","3班","4班","5班","6班","7班","8班","9班","10班","11 班","12班","13班","14班","15班","16班"],columns=["1","2","3","4","5","6","7","8","9","10","11","12","13","14","15","16"])
print(df) #生成16个班的对战结果
for i in range(16):
for j in range(16):
if s[i][j]==1:
m[j][1]+=s[i][j]
elif s[i][j]==-1:
#对生成的m列表里的16个班级的数据进行排序,以胜场数作为主要关键词进行降序排序,以输场数为次要关键词进行升序排序,使m列表中的元素按照班级排名从高到低的顺序依次排列。
代码略
i=0
while i<15:
n.append(m[i][0])
for jin range(i+1,16):
if :
n.append(m[j][0])
else:
break
k.append(n)
n=[]; i=j
print("获得冠军的班级有:",k[0],"班,获得亚军的班级有:",k[1],"班,获得季军的班级有:",k[2]," 班")