浙江省慈溪市2022-2023学年高二上学期信息技术2月期末考试卷
试卷更新日期:2023-03-22 类型:期末考试
一、选择题(本大题共10小题,每小题3分,共30分。每小题列出的四个备选项中只有一个是符合题目要求的,不选、多选、错选均不得分)
-
1. 阅读以下材料,回答第1-2题。
自2022年12月13日0时起,正式下线“通信行程卡”服务。“通信行程卡”短信、网页、微信小程序、支付宝小程序、APP等查询渠道将同步下线,同时同步删除用户行程相关数据。自新冠疫情爆发第一时间,上线大数据通信行程卡公益服务。近3年以来,已累计为广大用户提供了139亿次高效顺畅的查询服务,为疫情防控和复工复产提供了坚强保障。
(1)、下列有关数据的说法中,不正确的是( )A、通信行程卡所呈现的图像属于信息,具有载体依附性 B、通信行程卡呈现的是用户在一段时间内的行程状态,具有时效性 C、行程卡下线后,同步删除了用户的相关数据,保障了用户的个人数据安全 D、材料中提到的139是数据(2)、下列有关行程卡大数据说法中,正确的是( )A、通信行程卡大数据进行分析只需要抽样数据即可 B、通信行程卡大数据中蕴含着巨大的价值,因此其价值密度高 C、大数据的数据来源众多,半结构化和非结构化的数据在其中共存 D、分析通信行程卡大数据中,需要探求人们去各地的原因2. 使用UltraEdit软件观察字符, 部分界面如图所示。
下列说法中正确的是( )
A、图中共有4个ASCII 字符 B、字符“+”的十六进制内码是 2B 33 C、字符“2022”的十六进制内码是 32 30 32 32 D、字符“A”的内码用二进制表示是 0100 00103. 一个时长为10秒、400×300像素,256色、NTSC制式(30帧/秒)的未经压缩的AVI格式无声视频文件,压缩为MP4格式后的文件大小约为600KB,则其压缩比约为( )A、48 : 1 B、60 : 1 C、1500 : 1 D、1800 : 14. 小明对卡塔尔世界杯十分感兴趣,于是收集相关资料制作了一张有关卡塔尔世界杯的标签云,如下图。则下列有关该标签云的说法中,不正确的是( ) A、小明收集的文本资料属于非结构化数据 B、在制作该标签云的过程中需要进行分词,但不需要特征提取 C、在该标签云中,词语“卡塔尔”比“世界杯”的出现频率高 D、该标签云不需要显示文本数据中的全部词语5. 下列有关人工智能的说法正确的是( )A、lambda演算和原始递归函数不能完成图灵机的计算任务 B、从长远来看,人工智能技术带来的失业远大于就业 C、“无人驾驶汽车”属于跨领域人工智能 D、德州扑克人工智能Libratus通过与人类选手博弈不断提升棋力,采用的学习机制是强化学习6. 某算法的部分流程图如图所示。
A、小明收集的文本资料属于非结构化数据 B、在制作该标签云的过程中需要进行分词,但不需要特征提取 C、在该标签云中,词语“卡塔尔”比“世界杯”的出现频率高 D、该标签云不需要显示文本数据中的全部词语5. 下列有关人工智能的说法正确的是( )A、lambda演算和原始递归函数不能完成图灵机的计算任务 B、从长远来看,人工智能技术带来的失业远大于就业 C、“无人驾驶汽车”属于跨领域人工智能 D、德州扑克人工智能Libratus通过与人类选手博弈不断提升棋力,采用的学习机制是强化学习6. 某算法的部分流程图如图所示。
若输入m、n的值分别为1、100,执行该算法后,则下列说法正确的是( )
A、该流程图中有两个分支结构 B、该算法只能用流程图描述,不可用自然语言描述 C、该算法最后输出s的值为11 D、“m<=n”该语句执行了101次7. 字符串s的值为“Nothing is impossible”,则下列说法正确的是 ( )A、s[1]的值为“N” B、s[-1:-4:-1]的值为“elb” C、s[0:2]的值为“Not” D、s[ : : ]的值为 “”8. 有如下Python 程序段:lis=['a','b','c','d']
s=0
for i in lis:
c=ord(i)-ord('a')
s+=c
print(s)
程序运行后,输出s的值为( )
A、4 B、5 C、6 D、109. 有如下 Python 程序段:import random
a=[0]*6
for i in range(6):
x=int(random.random()*10)+1
if i%2==1:
a[i]=2*x+1
elif x%2==0:
a[i]=x//2
else:
a[i]=x-1
print(a)
执行该程序段后,列表 a 中的值可能是 ( )
A、3,11,4,19,2,13 B、3,11,7,9,2,3 C、9,3,1,23,4,17 D、3,3,9,0,19,8二、非选择题(本大题共3小题,8+6+6,共20分)
-
10. 学生选民数量统计。在中国,具有中国国籍且年满18周岁的人拥有选举权利,学校想要统计出截止到2022年12月31日年满18周岁的学生名单。学生的相关信息存储在”stu_info.txt”文件中,存储格式如下:
高一 1|谢乐|340421200606455914
高一 1|岑新奇|330282200407301529
说明:split( )函数实例。
x=“高一 1|岑新奇|330282200407301529”
y=x.spilt(“| ”)
得到的 y 中存放的数据是: [“高一 1”,“岑新奇”,“330282200407301529”]
(1)、请在划线处填入合适的代码。f=open("stu_info.txt","r",encoding="utf8")
namelist=[ ] #存放年满18周岁的学生名单
for line in f.readlines():
stu=line.split("|")
birth=
if birth<="20041231":
namelist.append()
print(namelist)
(2)、小明同学认为用Excel也可以处理这个问题,请在划线处填入合适的代码。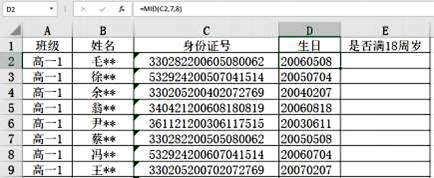
已知D7中的数据是通过D2单元格自动填充得到,D2中的公式是=MID(C2, 7, 8),则D7中的公式应该是。若E2中的公式是=D2<“20041231”,回车后,E2单元格中显示的结果是。(单选,填字母。A .True B .False C .“20041231”)随后对E列进行筛选就可以得到年满18周岁的名单。
11. 统计高一学生选课情况。高一学生要从物理、化学、生物、政治、历史、地理、技术这七门科目中选择3门作为选考科目,“1”表示已选择科目,数据存储在文件“xk.xlsx”中。⑴根据选课情况完成填充组合列(L列)。
⑵统计组合数量,并将选课组合人数最多的5个组合以柱形图的方式呈现(如图所示)。


import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel ("xk.xlsx")
plt.rc('font',**{'family':'SimHei'})
zh=[ ]
n=df.姓名.count()
xk=["物理","化学","生物","政治","历史","地理","技术"]
#处理组合名, 将组合名依次存入列表 zh 中 for i in range(n):
a=""
for x in xk:
if df.at[i,x]==1:
if x=="历史":
a=a+"史"
else:
a=a+x[0]
zh.append(a)
df["组合"]=
#将组合名填入 L 列
df1=df.groupby("组合",as_index=False).姓名.count()
df1.rename(columns={"姓名":"人数"},inplace=True) #将列标题”姓名”改成”人数” df1.sort_values("人数",,inplace=True)
df2=df1[0:5]
x=df2["组合"]
y=df2["人数"]
plt. (x,y)
plt.show ()
12. 试场号和座位号编号。每场考试都需要排试场号和座位号,小明同学设计了以下代码,实现了高一年级的试场号和座位号的自动编排,如图所示。请在划线处填入合适的代码。
import pandas
df=pandas.read_excel ("高一名册.xlsx")
n=df.姓名. #统计全校人数
a=30 #每个试场排 30 人
x=[ ] #存放 1~30 的编号
for i in range(a):
x.append()
sch=[ ]
zwh=[ ]
#处理30人满员的试场
for i in range(n // a):
zwh = zwh + x
sch = sch + [i + 1] * a
#处理最后一个不足30人的试场
for i in range():
zwh.append(i + 1)
sch.append(n // a + 1)
df.insert(3, "试场号", sch)
df.insert(4, "座位号", zwh)
df.to_excel ("高一名册.xlsx",index=False)