浙江省宁波市九校2022-2023学年高二上学期信息技术1月期末考试卷
试卷更新日期:2023-03-22 类型:期末考试
一、选择题(本大题共13小题,每小题2分,共26分。每小题列出的四个备选项中只有一个是符合题目要求的,不选、错选、多选均不得分)
-
1. 阅读下列材料, 回答问题。
全球气候变暖以及海水温度升高,导致珊瑚礁出现大片白化现象。珊瑚白化,是由于海水温度升高造成的。以往对珊瑚礁健康状况的监测主要靠人力完成,分析过程费时费力。现在,科学家们训练了一个人工智能(AI)系统,可以根据声音记录对珊瑚礁的健康状况进行分析。他们分别使用健康和退化珊瑚礁的大量声音记录训练了一种计算机算法,使机器能够学习两者之间的差异,随后分析了数百个小时的声音记录,快速便捷地识别出了珊瑚礁的健康状况,准确率不低于92%。
(1)、关于数据、信息和知识,下列描述不正确的是( )A、声音是数据的表现形式 B、材料中的92%是数据,不包含任何信息 C、数据的客观性为科学研究提供了可靠的依据 D、珊瑚白化是由于海水温度升高造成的,这是知识的体现(2)、下列关于人工智能的说法不正确的是( )A、语音识别应用了人工智能技术 B、人工智能技术将人类从繁重的工作中解脱出来 C、资料中的人工智能系统是符号主义方法的典型代表 D、深度学习是对原始数据所蕴含的特征模式进行学习的算法模型2. 下列有关信息的编码,描述正确的是( )A、最小的存储单位是位(bit) B、黑白图像的颜色位深度是2位 C、基本的ASCII码共有127个,用1个字节中的低7位编码 D、若某音频文件的量化位数为4位,则其量化值取值范围为0~33. 下列有关大数据及数据处理的说法,不正确的是( )A、处理大数据时一般采用分治思想 B、文本数据处理可应用于消费者意见数据的分析 C、大数据要分析的是全体数据,每一个数据都必须准确 D、探究具有关联性数据的分布关系, 可以使用散点图、气泡图4. 计算变量 s 的步骤如下:①变量s的初值为0,f的初值为-1,变量i的初值为2
②若i不超过10,则执行③,否则执行⑤
③s>s+f*i*(i+2),f>-f
④将i的值增加2,返回②
⑤输出变量s的值
则下列说法正确的是( )
A、该算法采用伪代码描述 B、该算法基本结构为分支结构 C、计算s的代数式可表示为:-2*4+4*6-6*8+8*10-10*12 D、若去掉步骤④中的“将i的值增加2”,则违反了算法的可行性特征5. 我国普遍采用EAN13条形码,它由13位数字组成,前3位表示国家,如图所示,条形码的前3位“690”表示中国大陆地区。若用字符串s存储条形码,则要获取“国家代码”的python表达式为( ) A、s[-13:-10:-1] B、s[-13:-10] C、s[1:4] D、s[0:2]6. 下列表达式的值和其他三项不同的是( )A、str(666)=='6'*3 B、-5//3==int(-2.8) C、2**3%5//3**2==0 D、["a"] in ["a","b","c"]7. 有如下Python程序段:
A、s[-13:-10:-1] B、s[-13:-10] C、s[1:4] D、s[0:2]6. 下列表达式的值和其他三项不同的是( )A、str(666)=='6'*3 B、-5//3==int(-2.8) C、2**3%5//3**2==0 D、["a"] in ["a","b","c"]7. 有如下Python程序段:dic={"苹果":[9.98,12.98],"香梨":[8.98,16.98]}
dic["苹果"][1]=15.98
dic["葡萄"]=[12.58,13.98]
print(dic)
该程序运行后输出的结果为( )
A、{"苹果": [15.98, 12.98], "香梨": [8.98, 16.98] } B、{"苹果": [9.98, 15.98], "香梨": [8.98, 16.98] } C、{"苹果": [15.98, 12.98], "香梨": [8.98, 16.98], "葡萄": [12.58, 13.98]} D、{"苹果": [9.98, 15.98], "香梨": [8.98, 16.98], "葡萄": [12.58, 13.98]}8. 有如下 Python 程序段: import pandas as pds=pd.Series(range(70,100,10))
for i in s:
print(i)
该程序运行后输出的结果为( )
A、 B、
B、 C、
C、 D、
D、 9. 小明制订了每周英语单词学习计划,本周单词保存在“word.txt”文件中,所有单词如图所示。
9. 小明制订了每周英语单词学习计划,本周单词保存在“word.txt”文件中,所有单词如图所示。
他编写了一个 Python 程序,检测学习情况,代码如下:
f=open("word.txt","r")
line=f.readline()
word=[]
while line:
temp=line.split() #将字符串以空格为分隔符号进行分割, 并存储在列表中
for i in temp:
if i[0]=='c' and 'e' in i:
word.append(i)
line=f.readline()
print(word)
执行该程序段后,输出的英语单词个数为( )
A、3 B、4 C、6 D、810. 有如下python程序段:for i in range(100,0,-1):
flag=True
m=i
for j in range(len(a)-1,-1,-1):
if m % 2!=a[j]:
flag=False
m//=2
if flag:
ans=i
break
print(ans)
已知列表a=[1,0,0,0,1,0,1],程序运行后,变量ans的值是( )
A、46 B、58 C、69 D、8111. 寻找最长无重复数字子串。输入一串仅由0~9组成的数字字符串,找出其中不含有重复字符的最长子串,若有多个长度相同的子串,则输出最后一个。如:输入数字字符串"1231255768",其最长的无重复数字子串有"3125"、"5678",则输出"5678",长度为4。实现该功能的python程序如下:defrepeat(s,x,y):#判断字符串s从位置x到y是否有重复字符
#无重复返回True(若x=y,为无重复),有重复返回Flase,代码略。
s1=input("请输入一个数字字符串: ")
len=len(s1)
left,right,maxlen=0,0,0
while right<len:
if not repeat(s1,left,right):
⑴
else:
if ⑵ :
maxlen=right-left+1
s2=s1[left:right+1]
⑶
print("最长无重复子串为: ",s2,"长度是: ",maxlen)
加框处的可选代码为:
①left+=1 ②right+=1 ③right-=1
④right-left>maxlen ⑤right-left+1>=maxlen
为使程序正确运行, 则程序段(1)(2)(3)处代码依次为( )
A、①④③ B、③⑤① C、②④① D、①⑤②12. 用python程序对分辨率为500*500的白色背景图像文件white.jpg(如图所示)进行处理,代码如下:
from PIL import Image
im = Image.open("white.jpg")
pix = im.load()
width = im.size[0] #获取图像宽度值
height = im.size[1] #获取图像高度值
for x in range(width):
for y in range(height):
if x<=width//2 and y<=height//2:
if x%50==0 or y%50==0 :
pix[x,y]=(0,0,0)
elif y>height//2:
if x==y or width-x==y :
pix[x,y]=(0,0,0)
im.show ()
white.jpg
程序执行后的图像效果是( )
A、 B、
B、 C、
C、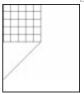 D、
D、
二、非选择题(本大题共3小题,其中第14小题10分,第15小题6分,第16小题8分,共24分)
-
13. 为了协助老师进行高效的试卷讲评,课代表小刘收集了单选题的相关数据,保存为“wrong.xlsx”文件,部分数据界面如图a所示,单选题共有13小题,每小题2分,共26分,用“1”表示该题是错选的。

图 a
(1)、小刘编写了如下python程序,计算每个同学的得分,输出满分同学,并将得分低于13分的同学学号加“*”标识,请在划线处填入合适的代码。import pandas as pd
import matplotlib.pyplot as plt
plt.rc("font", **{"family": "SimHei"}) #设置中文字体
df1=pd.read_excel ("wrong.xlsx")
df1["得分"]=26-df1.sum(axis=1)*2
for i in df1.index:
if :
df1.at[i,"学号"]="*"+df1.at[i,"学号"]
print( ) #输出满分的同学
(2)、小刘进一步统计了每个单选题的错误人数,并用图表分析错误人数最多的前6个单选题,请在划线处填入合适的代码。wnum={}
for i in df1.columns[1:14]:
wnum[i]=num
print(wnum) #输出结果如图b所示
{'单选 1': 11, '单选 2': 3, '单选 3': 3, '单选 4': 4, '单选 5': 5, '单选 6': 2, '单选 7': 9, '单选 8': 10, '单选 9': 7, '单选 10': 19, '单选 11': 9, '单选 12': 13, '单选 13': 26}
图b
#根据错误人数进行排序
df2=pd.DataFrame({"题号":wnum.keys( ),"错误人数":wnum.values( )})
df2_sort=df2.sort_values('错误人数', )
print(df2_sort) #输出结果如图c所示
#创建图表,分析错误人数最多的前6个单选题
df3 = df2_sort.
plt.title("错误人数排名前 6 的单选题")
plt.bar

plt.ylim(5,30)
plt.legend( )
plt.show ( )

图 c
(3)、要生成如图d所示的柱形图,第(2)题加框处应填写的代码是 (多选)
图 d
A、题号,错误人数 B、df3["题号"],df3["错误人数"] C、df3.题号,df3.错误人数,label="错误人数" D、df2_sort[:6].题号, df2_sort[:6].错误人数,label="错误人数"14. 寻找金蝉素数。素数是指大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。金蝉素数是指由1、3、5、7、9这5个奇数排列组成不重复的五位素数,它的中间三位数和最中间的一位数也都是素数的自然数,如“13597”是素数,“359”和“5”也是素数,则“13597”是金蝉素数。小乐编写了一个Python程序寻找金蝉素数,运行结果如图所示。 (1)、下列选项中可以填入加框处的代码是( ) (多选)A、2,n B、2,n+1 C、2,int(math.sqrt(n))+1 D、2,n/2+1 E、2,n//2+1(2)、Python 程序代码如下,请在划线处填入合适的代码
(1)、下列选项中可以填入加框处的代码是( ) (多选)A、2,n B、2,n+1 C、2,int(math.sqrt(n))+1 D、2,n/2+1 E、2,n//2+1(2)、Python 程序代码如下,请在划线处填入合适的代码import math
def isprime(n):
for i in range(
 ):
):if n%i==0:
break
else:
return True
return False
cicada=[]
c=0
for i in range(13579,99999,2):
a=[0]*10
temp=i
while temp!=0:
temp//=10
if a[1]+a[3]+a[5]+a[7]+a[9]==5:
x=i//100%10
y=
if and isprime(y) and isprime(i):
cicada.append(i)
c+=1
print("金蝉素数有: ",cicada)
print("共有:",c,"个")
15. 某字符串加密程序,其功能是:输入一个仅由小写英文字母组成的字符串,输出加密后的密文,加密规则如下所述:①将明文字符串分成3个字符一组,对每组字符进行②③处理,剩余不足3个的字符不做处理。
②随机产生由26个不重复的小写英文字母组成的密文串,将明文中的每组字符分别替换为密文串中对应的字符,若密文串如表1所示,则明文“abcdefghijkl”替换为“jpgntkwmaery”。
小写字母
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
v
w
x
y
z
密文串
j
p
g
n
t
k
w
m
a
e
r
y
l
d
c
q
f
i
x
u
h
z
b
o
v
s
表 1
③输入一串数字密钥(由1~9数字组成),密钥中每个数字依次为每组字符向右旋转次数,若密钥长度不足,则重复使用密钥,数字与对应旋转次数见表2。例如,数字密钥为“45”,则将第1组字符向右旋转1次,如“jpg”>“gjp”,将第2组字符向右旋转2次,如“ntk”>“knt”>“tkn”,第3组字符向右旋转1次,第4组字符向右旋转2次,依次类推。
数字
1
2
3
4
5
6
7
8
9
旋转次数
1
2
3
1
2
3
1
2
3
表 2
④将每组处理后的字符串顺序连接, 每组之间用“*”作为间隔符号, 再将分组剩余的字符倒序 连接, 得到密文。
程序运行结果如下:
 (1)、若明文为“abc”,随机产生的密文串如图所示,数字密钥为“13”,则密文为。(2)、实现上述功能的Python程序如下,请在划线处填入合适的代码。
(1)、若明文为“abc”,随机产生的密文串如图所示,数字密钥为“13”,则密文为。(2)、实现上述功能的Python程序如下,请在划线处填入合适的代码。
def jmdic(): #随机生成由26 个不重复的小写英文字母组成的密文串
#返回密文字符串,代码略
def rotate(array,k): #旋转
for i in range(k):
temp=array[len(array)-1]
for j in range( ):
array[j+1]=array[j]
array[0]=temp
ming=input("请输入明文:")
mkey=input("请输入一串数字密钥: ")
n=len(ming);m=len(mkey)
a=[]
dic=jmdic()
print("26 个小写字母对应的密文串:",dic)
for i in range(n//3): #对每组字符进行处理
a.append([]) #append():在列表末尾添加元素
for j in range(3):
a[i].append( dic[ ] )
] )
keynum=
k=(keynum-1)%3+1
rotate(a[i],k)
ans=""
for i in range(n//3): #将每组字符进行连接
for j in range(3):
ans+="*"*(i+1)
ans=ming[i*3+3:]+ans
print("密文为: ",ans)(3)、加框处代码有错,请更正。