浙江省宁波市三锋教研联盟2021-2022学年高二下学期信息技术期中联考试卷
试卷更新日期:2022-05-26 类型:期中考试
一、选择题(本大题共12小题,每小题2分,共24分)
-
1. 下列关于数据、信息和知识说法正确的是( )A、信息的存储必须依附于某种载体,但信息的表示不需要依附于某种载体 B、数据的生成过程一定需要人的参与 C、面对同样的信息,不同的理解会形成不同的知识 D、“学富五车”和“才高八斗”都是对智慧的形容2. 下列关于人工智能说法错误的是( )A、人工智能是一门多学科广泛交叉的前沿科学 B、AlphaGo Zero不依赖人类棋手数据而在自我博弈中不断提升棋力是行为主义的体现 C、AlphaGo于2016年战胜围棋九段棋手李世石,是符号主义的应用 D、机器学习主要研究计算机如何自动获取知识和技能,实现自我完善3. 下列选项中,哪个不是大数据的典型应用( )A、基于交易大数据分析用户的购买习惯 B、基于搜索引擎的搜索关键词分析社会热点 C、基于道路摄像头、地感线圈等数据分析城市交通情况 D、基于科技文献数据库检索某一领域研究进展4. 下列关于中文分词方法的描述中,属于基于统计的分词方法的是( )A、在分析句子时与词典中的词语进行对比,词典中出现的就划分为词 B、依据上下文中相邻字出现的频率统计,同时出现的次数越高就越可能组成一个词 C、让计算机模拟人的理解方式,根据大量的现有资料和规则进行学习,然后分词 D、依据词语与词语之间的空格进行分词5. 使用UltraEdit软件查看字符内码,部分界面如图所示:

下列说法正确的是( )
A、字符“之旅”是汉字,在计算机中存储时占4位 B、“10”的内码用十六进制表示为3AH C、图中除“之旅”之外,其他字符内码的十进制值均小于128 D、字符“P”的ASCII 码值是50H,则字符“N”的ASCII值是48H6. 一张大小为1024×768、颜色模式为16位色的未压缩BMP格式照片,将大小改成512×384,颜色模式改成256级灰度的未压缩BMP格式照片,则处理前后的照片存储容量比约为( )A、12:1 B、8:1 C、3:8 D、1:87. 某算法的部分流程图如图所示。执行这部分流程后,则输出ret的值为( )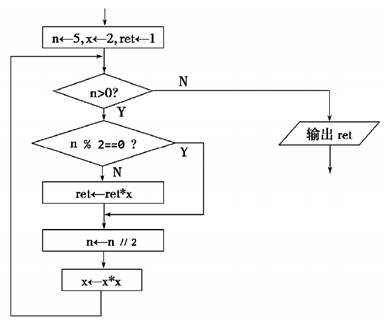 A、16 B、32 C、64 D、2568. 一个序列的入栈顺序为a,b,c,d,e,则该序列的出栈顺序不可能为( )A、b,a,d,c,e B、d,c,b,a,e C、d,c,e,a,b D、c,b,a,e,d9. 有如下程序代码:
A、16 B、32 C、64 D、2568. 一个序列的入栈顺序为a,b,c,d,e,则该序列的出栈顺序不可能为( )A、b,a,d,c,e B、d,c,b,a,e C、d,c,e,a,b D、c,b,a,e,d9. 有如下程序代码:import pandas as pd
data={ '姓名':['李商隐','欧阳修','李白',杜甫'],'借阅次数': [ 32,16,30,26]}
df1=pd. DataFrame (data, columns=[ '姓名','借阅次数'])
c = 0
for i in range ( len (df1 ['姓名'])):
if df1.at [i,'姓名'][0]= ='李':
c+= df1.at [i,'借阅次数']
print (c)
该程序运行后,输出的内容为( )
A、46 B、48 C、58 D、6210. 有如下Python程序段:a=input('请输入一串英文字符串:')
s=''
sum=0
for ch in a:
s=s+str(ord(ch)-ord(‘A’)-1)
for ch in s:
sum+=int(ch)
print(sum)
若输入字符串为‘ZBAX’(不包含前后引号),则输出结果为( )
A、8 B、13 C、17 D、411. 有如下Python程序段:n=10
m=0
d=[False]*10
for i in range(1,int(n**0.5)+1):
j=3*i
while j<n:
d[j]=not d[j]
j=j+3
for i in range(n):
if d[i]:
m=m+1
print(m)
执行该程序段后,变量m的值为( )
A、2 B、1 C、3 D、012. 执行该程序段后,输出的结果为4,则应输入的内容为( )n=int(input("请输入一个正整数"))
d={}
c=0
m=0
while n>0:
x=n % 10
if x not in d:
d[x]=1
else:
d[x]=d[x]+1
if d[x]==1:
c=c+1
n=n // 10
print(c)
A、135798 B、232458 C、20220320 D、24686482二、非选择题(本大题共4小题,其中第13小题5分,第14小题8分,第15小题6分,第16题7分,共26分)
-
13. 现有一关于2021年某酒店线上销售业绩源数据清单,包括客服、月份、订单金额等相关数据的Excel文件“销售.xlsx”,如“图a”所示。
 图a
图a使用Python读取表格中的数据,代码如下,根据题意填写划线部分:
import pandas as pd
df=pd.read_excel("销售.xlsx")
print() #筛选出商品原价大于等于1000的记录。
df1=df.groupby("客服",as_index=False)["订单金额"].sum()
df1.rename(columns={"订单金额":"订单总额"},inplace=True)
df2=
print( df2 ) #按“订单总额”降序排序后输出前10条记录
#以下代码功能为:绘制“各月份销售额”的折线图,结果如图b所示。
 图 b
图 bimport matplotlib.pyplot as plt
df3=df.groupby("月份",as_index=False)["订单金额"].sum()
plt.figure(figsize=(10,5))
plt.title('各月份销售额')
plt. (df3["月份"],df3["订单金额"])
plt.xlabel('各月份')
plt.ylabel("订单金额")
plt.show( )
14. 大写英文字母加密:步骤一、输入大写字母A-F的字符串,通过随机生成的keys列表进行匹配,找到相应的key,进行第1轮加密,得到相应的数字列表a。
步骤二、根据上述结果对加密后列表中的元素按偏移量K(K为正整数)发生偏移,每个元素从右往左向前移动K位,将偏移后结果存储在列表b中。
例如:


整体运行结果如下图所示:
 (1)、现有加密列表keys[4,5,7,1,3,9],需加密字母为“ABED”,则一轮加密后得到的数字列表a为:[],若偏移量为3,则二次加密后的列表b结果为:[]。(2)、请在划线处填入合适的代码。
(1)、现有加密列表keys[4,5,7,1,3,9],需加密字母为“ABED”,则一轮加密后得到的数字列表a为:[],若偏移量为3,则二次加密后的列表b结果为:[]。(2)、请在划线处填入合适的代码。import random
#随机生成 keys 列表
n=6
i=0
keys=[ ]
while i<n:
key=random.randint(1,9)
if key not in keys:
keys.append(key)
print("随机生成加密列表 keys:",keys)
#第1重加密:将输入的字母经过keys列表加密转换为a列表
a=[ ]
s=input("输入您要加密的字母(A-F):")
for i in s:
a.append(keys[])
print("经过第1轮keys列表加密后:",a)
#第2重加密:偏移加密
k=int(input("请输入偏移量K:"))
b=[0]*len(a)
for i in range(len(a)):
b[i]=a[]
print("经过第2轮加密后:",b)
15. 星期天小明来到动物园游玩,园内共有n 个景点,每个景点序号为0,1,2,3……至n-1。现在只知道每个景点有一条路连接下一个景点。小明想寻找能游玩景点个数最多的一种方案并且从其中一个景点出发,最后能够回到出发景点。如果游玩的景点个数一样,则优先考虑景点序号小的。例如,共有n=5 个景点,每个景点连接的下个景点分别是1,3,4,4,1
景点号
0
1
2
3
4
下一个景点号
1
3
4
4
1
方案一:从0号景点出发,则游玩线路为:0号→1号→3号→4号→1号,由于此方案无法回到出发点,则不考虑;
方案二:从1号景点出发,则游玩线路为:1号→3号→4号→1号,然后回到1号景点。最多可以玩3个景点。
现用Python程序模拟这个问题:
先输入景点总数:n ;则对应的景点为[0,1,2,3,4]
然后随机产生各景点所连接的下一个景点的序号,如:[1,3,4,4,1];
接着产生一个列表,如上表的信息则产生的列表s为:[[0,1],[1,3],[2,4],[3,4],[4,1]],
最后利用链表的方式来分析解决问题。
程序如下:

import random
#产生信息列表s
n=int(input("景点总数 "))
tt=[ ]; s=[ ]; c=0
while c < n :
t=random.randint(0,n-1)
if t !=c :
s.append([ ① ])
c+=1
print(s)
#枚举所有方案,寻找正确方案。
max=0
for head in range(n):
p=head
k=1
while k<=n and s[p][1]!=head:
k+=1
p=s[p][1]
if
 :
:max = k
maxp = head
print("小明最多能访问 %d 个景点"%(max))
#输出正确线路
p=maxp
while s[p][1]!=maxp:
print(s[p][0],end="→")
p=s[p][1]
print( ② )
(1)、横线处填写合适代码① ②
(2)、方框处修改代码16. 某程序功能如下:输入n,生成n*n的方阵,存于列表a,内容为1至9的随机整数。再对以(x0,y0)和(x1, y1)为对角顶点的矩形区域中的数据进行水平翻转,并将变换后的二维数组以矩阵形式输出。再输入小于n的四个数字(如a,b,c,d,四者关系必须满足a<c,b<d),用逗号间隔: 2,1,6,5 则左上角为a[1][2] ,右下角为a[5][6],则运行程序后,运行界面如图所示。 (1)、以上图为例,如果输入左上角+右下角的坐标为:2,3,7,5。水平翻转后,则元素a[3][4]的值在新数组保存在元素a[][](填写下标)中。(2)、代码如下并完成填空。
(1)、以上图为例,如果输入左上角+右下角的坐标为:2,3,7,5。水平翻转后,则元素a[3][4]的值在新数组保存在元素a[][](填写下标)中。(2)、代码如下并完成填空。#生成n*n的矩阵
import random
n=int(input(‘输入n,产生n*n的方阵:’ ))
a=[[random.randint(1,9) for i in range(n)] for j in range(n)]
for i in a:
print(i)
print( )
x,y=[],[]
xy=input("请输入左上角+右下角坐标:") #输入左上角坐标+右下角坐标,用逗号分隔数字。如:"2,1,14,13"
xy=xy+","
c,j=0,0
for i in range(len(xy)):
if xy[i]==",":
if :
x.append(int(xy[j:i]))
else:
y.append(int(xy[j:i]))
c=c+1
for i in range(y[0],y[1]+1,1):
for j in range(x[0],(x[0]+x[1])//2+1,1):
a[i][j],a[i][]=a[i][],a[i][j]
for i in range(len(a)):
print(a[i])