浙江省诸暨二高2020-2021学年高一下学期信息技术期中考试试卷
试卷更新日期:2021-08-27 类型:期中考试
一、选择题(本大题共12小题,每小题2分,共24分)
-
1. 在数据整理中2020/2/30属于数据问题中的 ( )A、数据缺失 B、数据重复 C、逻辑错误 D、格式不一致2. 下列关于大数据处理的说法,错误的是 ( )A、处理大数据一般采用分治思想 B、数据采集只能收集结构化数据 C、图计算主要针对图数据 D、并行处理能节省复杂问题的处理时间3. 下列关于 Hadoop的功能说法错误的是( )A、将大规模海量数据以文件的形式、用多个副本保存在不同的存储节点中 B、Reduce函数可归纳节点任务的计算结果 C、分布式数据库HBase采用基于列的存储方式 D、能够快速处理大规模实时数据的计算与分析4. 下列 DataFrame常用函数语句及其对应解释错误的是( )A、drop( )———删除数据 B、read_excel( )———读取Excel文件 C、append( )———合并 DataFrame对象 D、sort_values( )———排序5. 文本数据处理的一般过程不包括( )A、数据共享 B、特征提取 C、数据分析 D、结果呈现6. 下列关于大数据在电子商务方面的应用,说法错误的是( )A、在交易、营销、供应链、仓储等环节产生了大量数据 B、通过电商平台提供的精准营销服务是基于用户购买行为的大数据 C、在供应链管理中,根据商品销售情况和市场预期数据,依靠推断模型,实现商品自动补货 D、购物网站基于大数据挖掘和分析,变得越来越智慧7. 如图所示为某导航系统的导航路径。现在,人们的日常出行越来越离不开导航系统,人们也日益感受到智能交通带来的便利。下列有关智能交通的说法中错误的是( )
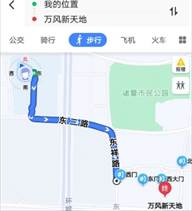 A、智能交通整合了物联网、大数据、云计算、人工智能等技术 B、智能交通提高了交通效率但降低了安全性 C、智能交通最终使交通运输服务和管理智能化 D、智能交通对数据进行实时采集、传输和处理8. 人工智能的神经网络研究属于 ( )A、符号主义 B、联结主义 C、行为主义 D、试错主义9. 下列关于人工智能对社会的影响的叙述中,错误的是 ( )A、人工智能改善人类生活,使人们居家、出行、购物、医疗等日益便捷 B、人工智能促进经济发展,推动人工智能与实体经济结合,是加快实体经济转型升级的必然发展方向 C、人工智能技术将人类从繁琐工作中解脱出来的同时,也会取代一些工作岗位,但从长期来看,科技带来的就业远大于失业 D、未来人类与智能机器必定可以安全、和谐地相处,因此对人工智能理论和技术在一些方面超越人类的表现无需警惕10. 某DataFrame对象score包含“准考证号”“学校名称”“姓名”“总分”“排名”等数据列,下列语句中,可以以学校为单位,输出各校学生“总分”平均值的是( )A、print(score.groupby(“学校名称”,as_index=False).mean( )) B、print(score.groupby(“总分”,as_index=False).mean( )) C、print(score.groupby(“学校名称”,as_index=False).排名.mean( )) D、print(score.sort_index(“学校名称”,as_index=False).describe( ))11. 小明参加课外活动小组,对盆栽中某一枝条做好标记,记录28天内该枝条的生长情况,每周日记录一次,四次记录结果分别为8.8cm、10.1cm、10.9cm、11.4cm。他使用Python编码。制作了关于枝条长度(单位:cm)的柱形图,代码及柱形图如下图所示,代码空白处应填。 ( )
A、智能交通整合了物联网、大数据、云计算、人工智能等技术 B、智能交通提高了交通效率但降低了安全性 C、智能交通最终使交通运输服务和管理智能化 D、智能交通对数据进行实时采集、传输和处理8. 人工智能的神经网络研究属于 ( )A、符号主义 B、联结主义 C、行为主义 D、试错主义9. 下列关于人工智能对社会的影响的叙述中,错误的是 ( )A、人工智能改善人类生活,使人们居家、出行、购物、医疗等日益便捷 B、人工智能促进经济发展,推动人工智能与实体经济结合,是加快实体经济转型升级的必然发展方向 C、人工智能技术将人类从繁琐工作中解脱出来的同时,也会取代一些工作岗位,但从长期来看,科技带来的就业远大于失业 D、未来人类与智能机器必定可以安全、和谐地相处,因此对人工智能理论和技术在一些方面超越人类的表现无需警惕10. 某DataFrame对象score包含“准考证号”“学校名称”“姓名”“总分”“排名”等数据列,下列语句中,可以以学校为单位,输出各校学生“总分”平均值的是( )A、print(score.groupby(“学校名称”,as_index=False).mean( )) B、print(score.groupby(“总分”,as_index=False).mean( )) C、print(score.groupby(“学校名称”,as_index=False).排名.mean( )) D、print(score.sort_index(“学校名称”,as_index=False).describe( ))11. 小明参加课外活动小组,对盆栽中某一枝条做好标记,记录28天内该枝条的生长情况,每周日记录一次,四次记录结果分别为8.8cm、10.1cm、10.9cm、11.4cm。他使用Python编码。制作了关于枝条长度(单位:cm)的柱形图,代码及柱形图如下图所示,代码空白处应填。 ( ) A、"8.8,10.1,10.9,11.4" B、"8.8","10.1","10.9","11.4" C、8.8,10.1,10.9,11.4 D、[8.8,10.1,10.9,11.4]12. 有一段 Python代码及其运行结果如下
A、"8.8,10.1,10.9,11.4" B、"8.8","10.1","10.9","11.4" C、8.8,10.1,10.9,11.4 D、[8.8,10.1,10.9,11.4]12. 有一段 Python代码及其运行结果如下
小明在代码中插入了语句“df_delc=df.drop(0)”, 其余不做修改,那么运行这段修改后的代码,其运行结果为( )
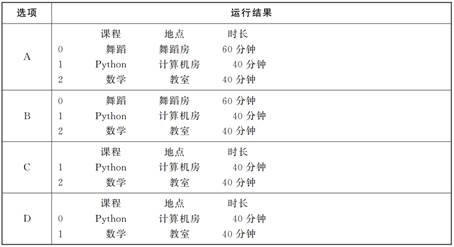 A、A B、B C、C D、D
A、A B、B C、C D、D二、非选择题(本大题共4小题,6+6+6+8,共26分)
-
13. 小方使用Excel分析某网店2018年第四季度销售的相关数据,部分界面如图1所示:
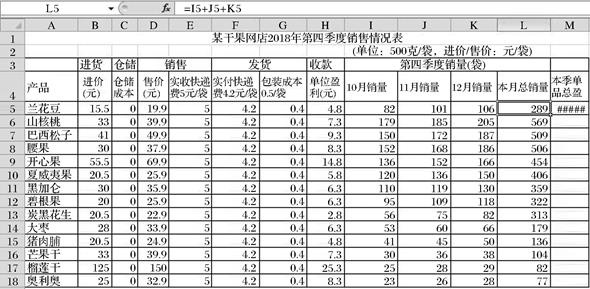
图1
(1)、M5单元格出现“#####”符号,,希望正常显示则需要(2)、表中本季总销量的计算是通过在L5单元格中输入公式,并将公式自动填充到L18单元格后得到的,请问L8单元格中的公式是。(3)、若要对该网店2018年第四季度销售情况以“本月总销量”为主要关键字降序排序,则排序时选择的数据区域是(4)、建立了一张反应本季单品总盈的柱型图,如图2所示:应选择的数据区域是 , 图表生成后,小方对本季单品总盈这列数据进行了 操作,已生成的图表(填“会”或“不会”)发生变化。
操作,已生成的图表(填“会”或“不会”)发生变化。 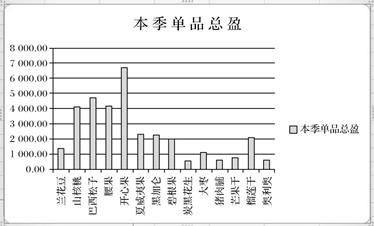
图2
(5)、对表中各产品的“进价(元)”和“12月销量”的数据进行筛选操作,筛选条件设置如图3所示,则按此设置筛选出的产品有个。
图3
14. 如图1是某校信息技术成绩概况表,分析回答下列问题:
图1
(1)、对区域A1:J1 执行了“合并单元格”操作,合并后的单元格名称为(2)、如图1所示,区域C3:C14是通过公式计算得到的,要实现计算,可以选择区域中的C3单元格,输入公式 , 然后利用自动填充功能完成其他单元格的计算。(提示:合格数=实考数*(1-不及格率))(3)、若要将表格中的数据对班级按“优秀率”进行从高到低的排序,应选择的排序数据区域为。(4)、若要用图表直观显示各班实考人数占全校实考人数的占比情况,应选择的数据区域是。(5)、根据图1中数据制作的图表如图2所示,在下列操作中,能引起图表发生变化的是(多选,填序号:A .以“平均分”为关键字对表格数据进行排序;B .选定区域D3:D14设置单元格格式,保留2位小数;C .把单元格D6的数据手工修改为73.4;D .通过函数计算出全校平均分,填在单元格D15 )。
图2
15. 学校对各班级的文艺汇演成绩做了评分,并利用Excel 软件进行数据处理,部分界面如图1所示。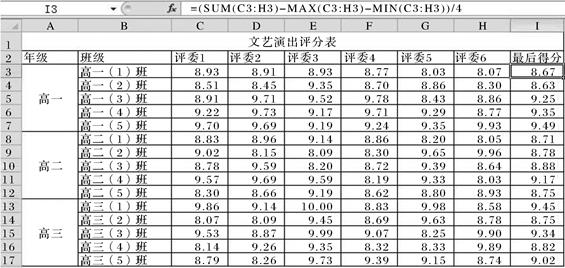
图1
(1)、 用公式计算出各班级得分,可在I3 单元格输入公式,再利用自动填充得到其他班级得分,则I6 单元格上的公式为。(2)、 若将I3:I17单元格的数值小数位数设置为0,则I3单元格中的值(单选:填字母:A .变大/B .不变/C .变小)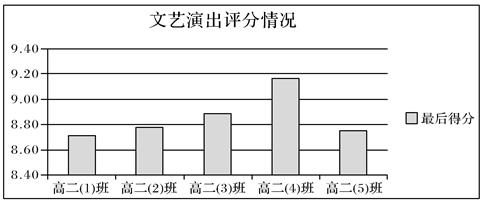
图2
(3)、 根据数据表中的数据制作的图表如图2所示,创建该图表的数据区域为。(4)、 若只对“高二”年级以“最后得分”为主要关键字降序排序,则排序时选择的数据区域是。(5)、将各年级最后得分最高的班级设为该年级的一等奖,下列方法可得到高二年级一等奖班级的是 (多选,填字母)。A、选择区域B8:I12,再按“列I”为关键词进行降序排序后,该区域的第1 条记录为高二年级一等奖班级 B、先筛选出“班级”开头是“高二”的记录,再筛选出“最后得分”为最大1 项的记录,筛选结果即为高二年级一等奖班级 C、先筛选出“最后得分”为最大1 项的记录,再筛选出“班级”包含“高二”的记录,筛选结果为高二年级一等奖班级 D、先按“最后得分”升序排序,再筛选出“班级”包含“高二”的纪录,最后一条记录为高二年级一等奖班级16. 某市普通高中选课数据如图1所示,学生从地理、化学、生物等科目中选择三门作为高考选考科目,“1”表示已选择的选考科目。使用Python编程分析每所学校各科目选考的总人数、全市各科选考总人数及其占比,经过程序处理后,保存结果如图2
图1
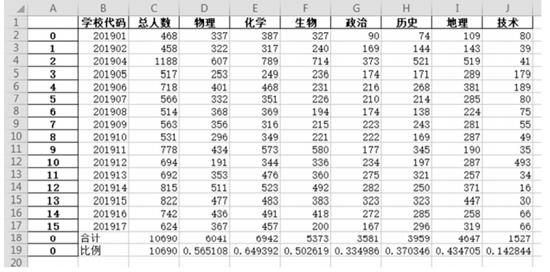
图2
实现上述功能的Python程序如下:
import pandas as pd
import itertools
#读数据到pandas的 DataFrame结构中
df= ① (”xk73.csv”,sep=‘.’,header=‘infer’,encoding=‘utf-8’)
km=[‘物理’ ,‘化学’ ,‘生物’ ,‘政治’ ,‘历史’ ,‘地理’ ,‘技术’ ]
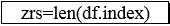
#按学校分组计数
sc=df.groupby(‘ ② ’,as_index=False).count( )
#对分组计数结果进行合计,合计结果转换为 DF结构并转置为行
df_sum=pd.DataFrame(data=sc.sum()).T
df_sum[‘学校代码’]=‘合计’
#增加"合计"行
result=sc.append(df_sum)
#百分比计算
df_percent=df_sum
df_percent[‘学校代码’]=‘比例’
for k in km:
per=df_percent.at[0,k]/zrs
df_percent[k]=per
#增加"百分比"行
result=result.append(df_percent)
#删除"姓名"列
result= ③
#修改"学生编号"为"总人数"
result=result.rename(columns={‘学生编号’:‘总人数’})
#保存结果,创建 Excel文件.生成的 Excel文件result.to_excel("学校人数统计.xlsx")
(1)、请在划线处填入合适的代码① ② ③
(2)、加框处语句的作用是